LangChain 與 LlamaIndex 是 AI 應用開發實戰最常用的兩大框架。如果你想做的不只是「調 ChatGPT API 寫個聊天機器人」,而是要建立一套有記憶、會用工具、能查內部資料的 AI 應用,那麼學會其中一個框架是必經之路。本指南會帶你理解兩者的差異、各自的強項,以及實戰時的選擇判斷。
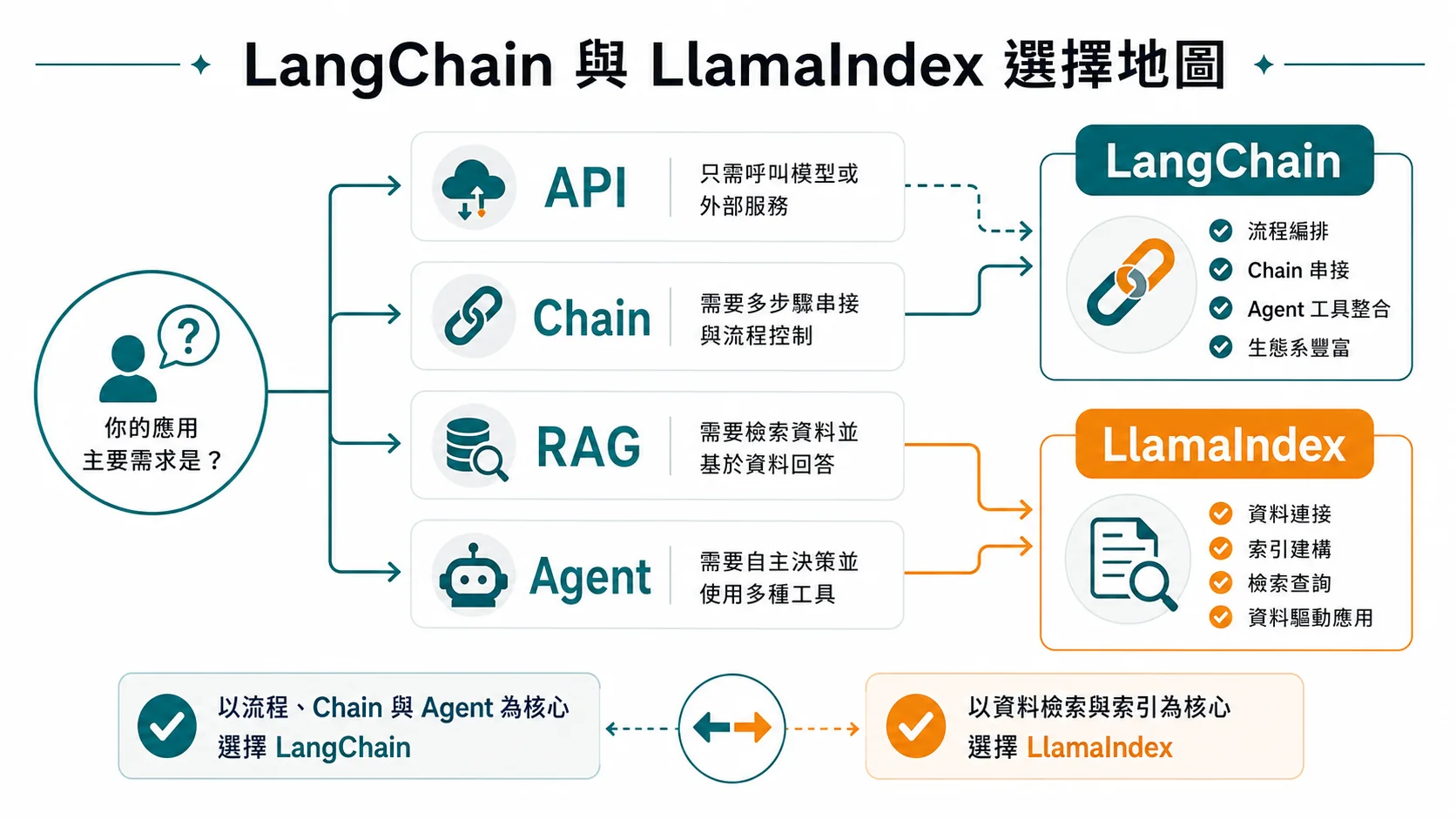
簡單一句話先定位:LangChain 是一個「把 LLM 組合成工作流」的通用框架,它提供 Prompt 模板、Chain 串接、Agent 決策、工具呼叫、記憶管理等全套積木;LlamaIndex 則是一個「把你的資料餵給 LLM」的 RAG 專用框架,它的核心價值在於文件載入、切割、Embedding、向量檢索這條資料管線的極致優化。兩者有重疊但不是替代品,搞清楚這個分界,才不會在技術選型時走冤枉路。
🦜 為什麼需要框架?
直接呼叫 API 可以做很多事,但當你需要把多個步驟串起來,框架能幫你省下大量開發時間。自己用 requests 或 openai SDK 寫當然也做得出來,但一旦你需要管理多輪對話記憶、整合向量資料庫、讓模型自主選工具、處理 retry 與 rate limit,程式碼會迅速膨脹成難以維護的巨獸。框架的價值不是「做了你做不到的事」,而是把這些重複出現的基礎建設抽象成可組合的元件。
💡 一句話理解 LangChain / LlamaIndex = AI 開發的 Express.js / Django。 你可以手寫 HTTP server,但用框架更快更穩。
何時用框架 vs 直接呼叫 API
| 場景 | 建議 |
|---|---|
| 單次對話、簡單問答 | 直接用 API |
| 多步驟 Chain(先分析 → 再摘要 → 再翻譯) | ✅ 用框架 |
| RAG 系統 | ✅ 用框架 |
| AI Agent(使用多種工具) | ✅ 用框架 |
| 對話記憶管理 | ✅ 用框架 |
| 需要最大控制力和最小依賴 | 直接用 API |
一個實用判斷法:如果你的需求用 50 行以內的 Python 就能寫完,不要上框架;如果專案會長期維護、會有人接手、會持續加功能,那麼早一點引入框架,比之後重構便宜很多。
🆚 LangChain vs LlamaIndex
| 面向 | LangChain | LlamaIndex |
|---|---|---|
| 定位 | 通用 AI 應用框架 | 資料索引 + RAG 框架 |
| 強項 | Agent、Chain、工具整合 | 資料載入、索引、檢索 |
| 學習曲線 | ⭐⭐⭐(較陡) | ⭐⭐(較平) |
| 彈性 | 極高(什麼都能做) | 高(RAG 場景極強) |
| 社群 | 最大 | 次大 |
| 適合 | 多種 AI 應用 | 專注 RAG 和知識問答 |
💡 簡單選法 做 RAG/知識問答 → LlamaIndex(更簡單、更專注) 做 Agent/複雜工作流 → LangChain / LangGraph(更彈性) 兩者可以混用——LlamaIndex 做索引,LangChain 做 Agent
哲學差異:LangChain 的世界觀是「LLM 是一個會思考的計算單元,我要把它塞進任意工作流裡」,所以它的 API 長得像一個作業系統——什麼都抽象、什麼都可以組合。而 LlamaIndex 的世界觀是「LLM 是一個會讀文件的分析師,我要把我的資料以最有效的方式餵給它」,所以它的 API 長得像一個資料管線——文件進、答案出,中間的索引、切割、檢索都有最佳預設。
台灣/繁中開發者的考量:LangChain 對多語言場景的支援比較原生,Prompt 模板好改、工具整合多,適合做客服機器人、跨系統 Agent 這類業務應用。LlamaIndex 在處理企業內部的中文 PDF、Notion 文件、SharePoint 知識庫時,預設的 SimpleDirectoryReader 與 SentenceSplitter 省下很多工夫,但繁中文件要注意 chunk 切割點不要切在句子中間,最好自己測一下切割品質。想搭配本地開源模型(例如 Qwen3 系列)時,兩者都有現成 adapter,LlamaIndex 對本地 Embedding 模型的支援略成熟。
常見遷移路徑:多數團隊的實際走法是「先用 LlamaIndex 把 RAG Demo 跑起來驗證價值,之後要加工具、加 Agent、加複雜工作流時,外層包一層 LangChain 或 LangGraph」。少數團隊反過來——先用 LangChain 做 Agent,後來發現 RAG 這塊 LangChain 寫太繁瑣,改用 LlamaIndex 做 Retriever 再塞回 LangChain Chain 裡。兩個框架有官方互通層,混用是合法選擇,不用非黑即白。
🔗 LangChain 實戰
安裝
pip install langchain langchain-openai langchain-community基礎 Chain(串接多個步驟)
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 建立 LLM
llm = ChatOpenAI(model="gpt-4o", temperature=0.7)
# 定義 Prompt 模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一位資深的 {expertise} 專家。用繁體中文回答。"),
("user", "{question}")
])
# 建立 Chain:Prompt → LLM → 解析輸出
chain = prompt | llm | StrOutputParser()
# 執行
result = chain.invoke({
"expertise": "AI 工程",
"question": "RAG 和 Fine-tuning 怎麼選?"
})
print(result)這段在做什麼:|(pipe)運算子是 LangChain 的 LCEL(LangChain Expression Language)語法,它把三個元件串成一條資料流——Prompt 模板接收 dict 參數、輸出 ChatPromptValue;LLM 接收 ChatPromptValue、輸出 AIMessage;StrOutputParser 把 AIMessage 裡的文字抽出來變成 str。這種 pipe 寫法不只是語法糖,背後支援自動的批次、串流、非同步與追蹤。
常見錯誤:(1) temperature 設太高(0.7+)卻期待穩定輸出——這會讓每次結果不一樣,需要一致性的場景請設 0 或 0.2。(2) {expertise} 變數名稱在模板和 invoke 對不上,會噴 KeyError。(3) 忘記裝 langchain-openai,或者 OPENAI_API_KEY 沒設環境變數。
除錯技巧:在 Chain 前面加一個 lambda 印中間結果——chain = prompt | (lambda x: print(x) or x) | llm | StrOutputParser(),或者直接用 LangSmith 看每一步的輸入輸出。
多步 Chain(先分析 → 再摘要)
# Chain 1:分析文章
analyze_prompt = ChatPromptTemplate.from_template(
"分析以下文章的重點和論述邏輯:\n\n{article}"
)
analyze_chain = analyze_prompt | llm | StrOutputParser()
# Chain 2:根據分析結果生成摘要
summarize_prompt = ChatPromptTemplate.from_template(
"根據以下分析,寫一段 100 字的摘要:\n\n{analysis}"
)
summarize_chain = summarize_prompt | llm | StrOutputParser()
# 串接:分析 → 摘要
full_chain = (
analyze_chain
| (lambda analysis: {"analysis": analysis})
| summarize_chain
)
result = full_chain.invoke({"article": "你的長文章..."})這段在做什麼:把兩個獨立的 Chain 接起來,中間用一個 lambda 把前一步的 str 輸出包成下一步需要的 dict 輸入。這種「形狀轉換」是多步 Chain 的高頻操作,因為每個 Chain 的輸入輸出型別不同。
常見錯誤:(1) 忘記中間的 {"analysis": analysis} 包裝,下一步會因為拿到 str 而不是 dict 爆炸。(2) 第一步輸出太長(例如完整文章分析),第二步 Prompt 塞不下,觸發 context window 爆表——這時候要在中間加一層強制截斷或摘要。(3) 每一步都呼叫 LLM,成本會乘上步數,複雜 Chain 的 token 費用容易失控。
除錯技巧:拆開跑,analyze_chain.invoke(...) 先確認第一步正常,再確認第二步,最後才串起來。
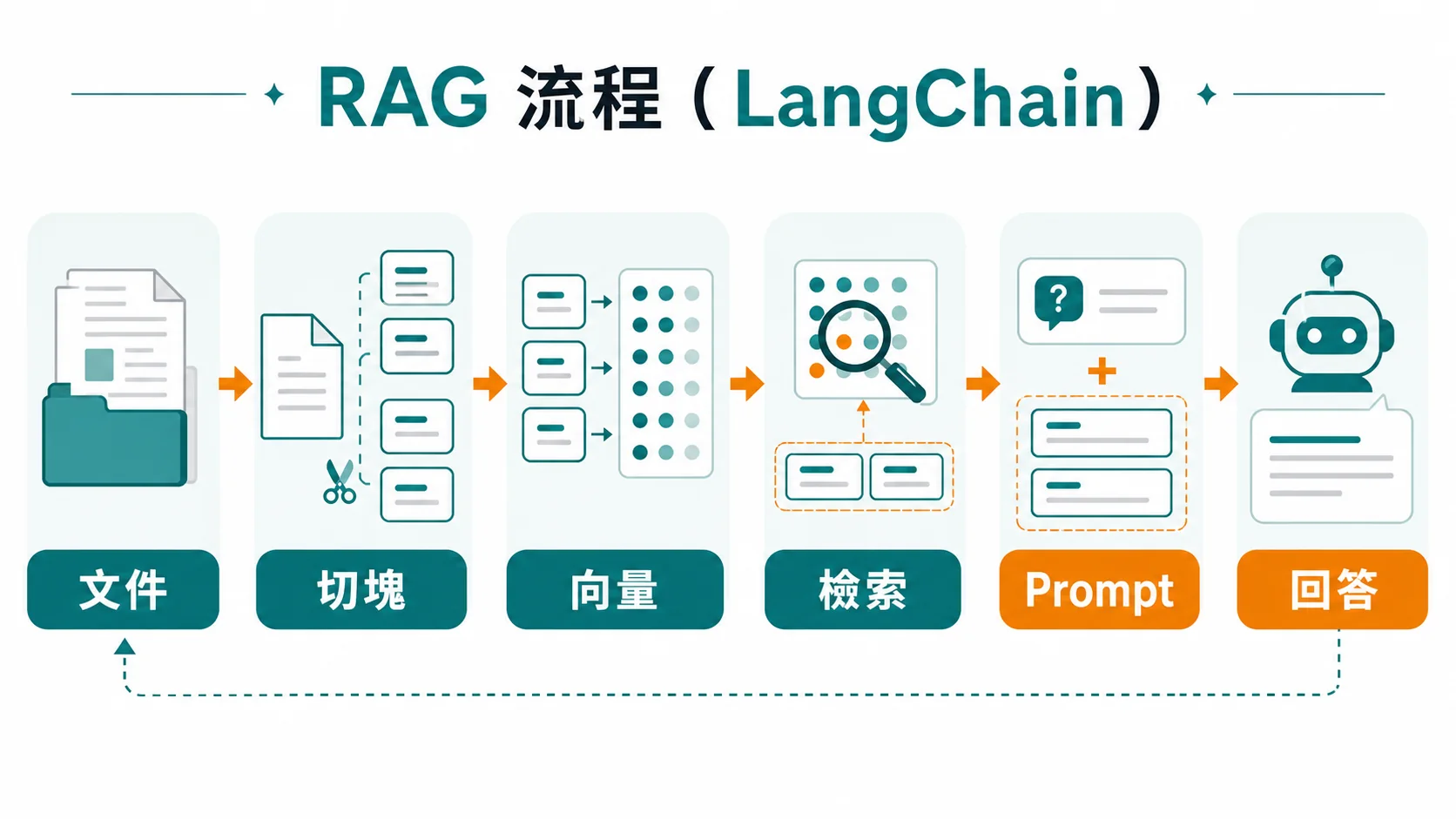
RAG Chain
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.runnables import RunnablePassthrough
# 1. 建立向量資料庫
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=50
)
# 載入文件並切割
docs = text_splitter.split_text(your_document)
vectorstore = Chroma.from_texts(docs, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# 2. RAG Prompt
rag_prompt = ChatPromptTemplate.from_template("""
根據以下參考資料回答問題。如果資料中沒有相關資訊,請說「我沒有找到相關資訊」。
參考資料:
{context}
問題:{question}
""")
# 3. 建立 RAG Chain
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
| StrOutputParser()
)
# 4. 使用
answer = rag_chain.invoke("怎麼退貨?")這段在做什麼:這是一個完整的 RAG 流程——使用者問題進來後,先被 retriever 拿去向量資料庫找 top-3 相似段落當 context,然後連同問題一起塞進 Prompt 模板,最後交給 LLM 產出答案。RunnablePassthrough() 的作用是「把輸入原樣傳給下一步」,因為 question 不需要被 retriever 處理。
常見錯誤:(1) chunk_size 設得不對——中文文件 500 字可能切掉半句,建議 400-800 之間實測。(2) k=3 召回太少,重要資訊漏掉;k=10 又會稀釋相關性、增加 token 成本。(3) Prompt 沒寫「資料中沒有就說沒有」,模型會幻覺編造。
除錯技巧:檢索品質先驗證——直接 retriever.invoke("怎麼退貨?") 看召回段落是否相關。如果召回就錯了,後面 LLM 再強也沒救,要回頭改切割策略或改用更好的 Embedding 模型。
🦙 LlamaIndex 實戰
安裝
pip install llama-index llama-index-llms-openai llama-index-embeddings-openai最簡 RAG(5 行搞定)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 1. 載入資料夾中的所有文件(PDF、TXT、Markdown…)
documents = SimpleDirectoryReader("./data").load_data()
# 2. 建立索引(自動切割、Embedding、存入向量 DB)
index = VectorStoreIndex.from_documents(documents)
# 3. 開始問答
query_engine = index.as_query_engine()
response = query_engine.query("公司的退貨政策是什麼?")
print(response)這段在做什麼:LlamaIndex 把 RAG 的每一步都藏在預設裡——SimpleDirectoryReader 會自動辨識檔案類型呼叫對應 parser、VectorStoreIndex 預設用 OpenAI Embedding 切好存進記憶體內建的向量儲存,as_query_engine 建一個「檢索 + 生成」的查詢引擎。5 行跑起來,但預設值不一定適合你的資料。
向量儲存怎麼選:(1) FAISS——本地、免費、快、但不持久化,重跑要重算 Embedding,適合原型與小專案。(2) Chroma——本地、免費、有持久化、SQL 查詢,適合中型專案與自架。(3) Pinecone / Weaviate / Qdrant——雲端託管、可水平擴展、有混合搜尋,適合生產環境與大型知識庫。選擇原則:文件數 < 10 萬用 Chroma,> 100 萬用 Pinecone,兩者之間看有沒有人維運需求。
RAG 答非所問怎麼診斷:(1) 先看 response.source_nodes 召回的段落,如果段落根本不相關 → Embedding 或切割問題。(2) 如果段落相關但答案錯 → Prompt 或 LLM 問題,換模型或改 Prompt。(3) 如果答案接近但缺細節 → similarity_top_k 調高,讓更多段落進 context。
成本估算:用 text-embedding-3-small,1M token 約 USD 0.02。假設中文 1 token ≈ 1.5 字,一份 10 萬字的文件 Embedding 一次成本約 USD 0.0013,便宜到可忽略。但每次查詢會呼叫 LLM(gpt-4o 輸入 USD 2.5 / 1M token),如果有 1 萬次查詢、每次塞 3000 token context,一天 USD 75 是常態——成本爆點在查詢,不在 Embedding。
進階:自訂 RAG 參數
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
# 自訂全域設定
Settings.llm = OpenAI(model="gpt-4o", temperature=0)
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
Settings.node_parser = SentenceSplitter(chunk_size=512, chunk_overlap=50)
# 建立索引
index = VectorStoreIndex.from_documents(documents)
# 自訂查詢(取 top-5 相關段落)
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("怎麼退貨?")
# 查看檢索到的段落
for node in response.source_nodes:
print(f"相似度: {node.score:.3f}")
print(f"內容: {node.text[:100]}...")這段在做什麼:透過 Settings 全域覆寫預設、用 similarity_top_k 加大召回、最後列印 source_nodes 做 RAG 品質檢驗。生產環境的 LlamaIndex 專案幾乎都長這樣——沒有人會裸用 5 行版本上線。
相似度分數怎麼讀:cosine similarity 範圍 01,實務經驗 > 0.75 通常相關、0.60.75 邊緣、< 0.6 多半是噪音。如果 top-5 都在 0.5 以下,表示你的問題根本沒被 Embedding 模型理解——這時候要考慮用混合搜尋(BM25 + 向量)或改用更強的 Embedding 模型。
🤖 LangGraph:建 Agent
LangGraph 是 LangChain 團隊專為 AI Agent 設計的框架。
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_community.tools import TavilySearchResults
from langchain_core.tools import tool
# 自訂工具
@tool
def calculate(expression: str) -> str:
"""計算數學表達式。輸入數學算式,回傳計算結果。"""
try:
return str(eval(expression))
except:
return "計算錯誤"
# 建立 Agent(帶搜尋和計算工具)
agent = create_react_agent(
ChatOpenAI(model="gpt-4o"),
tools=[TavilySearchResults(max_results=3), calculate],
)
# Agent 會自主決定要用哪個工具
result = agent.invoke({
"messages": [{
"role": "user",
"content": "台積電目前股價是多少?如果我買 10 張,要花多少錢?"
}]
})
# Agent 會:1. 搜尋股價 2. 用計算器算出總金額為什麼需要 LangGraph,不是 LangChain Agent:舊版 LangChain 的 AgentExecutor 是一個「黑盒 while 迴圈」,你給它工具、給它 Prompt,它自己跑到收斂為止——問題是你看不到中間狀態、不能暫停、不能人工介入、不能分支。LangGraph 把 Agent 重寫成狀態機 + 圖,每個節點是一個動作(呼叫 LLM、呼叫工具、條件判斷),邊是狀態轉移,整個流程可視化、可 checkpoint、可 human-in-the-loop,更接近真實生產系統的需求。
LangGraph vs 單純寫 loop:如果你的 Agent 只需要「LLM 決定工具 → 執行 → LLM 看結果 → 決定下一步」這種簡單 ReAct 迴圈,自己用 function calling 寫一個 while 反而更清楚、更少依賴。詳細取捨可參考 AI Agent 實作教學。LangGraph 的價值在於多 Agent 協作、需要 checkpoint 中斷再續、需要條件分支、需要人工審核節點這類複雜場景——單 Agent 簡單迴圈用它反而殺雞用牛刀。
除錯有狀態的 Agent:(1) 開 LangSmith 追蹤,每個節點的 state 前後都看得到。(2) 用 agent.get_state(config) 印出當前狀態,確認記憶沒亂掉。(3) 遇到 Agent 鬼打牆(同一個工具呼叫 5 次還是錯),通常是工具描述寫得不夠精確,LLM 根本不知道該傳什麼參數——改 docstring 比調 Prompt 有用。
⚠️ 常見 Anti-Pattern
| Anti-Pattern | 問題 | 正確做法 |
|---|---|---|
| LangChain 包一切 | 簡單任務也用框架,增加複雜度 | 簡單場景直接用 API |
| 不看中間結果 | 鏈很長但不知道哪步出錯 | 加 verbose=True 除錯 |
| 忽略版本差異 | LangChain 更新很快,舊教學可能不適用 | 鎖定版本、看官方文檔 |
| 全用預設設定 | Chunk size、top_k 用預設值 | 用你的資料測試最佳參數 |
LangChain 包一切:實務上看到最多的錯是「做一個翻譯 API 也用 LangChain」。一個 Prompt、一次 LLM 呼叫、固定輸出——這種場景 openai SDK 三行就搞定,用 LangChain 反而要載入一堆抽象、debug 時要穿越多層框架。判斷原則:如果你畫不出超過兩個節點的流程圖,就不需要框架。
不看中間結果:RAG Chain 答錯了,很多人第一反應是「換模型」,但 80% 的情況問題出在檢索階段——召回的段落根本不相關。每次 Chain 出錯先印中間結果,確認是哪一步爛掉,否則你會在錯誤的層級浪費時間。LangSmith / LangFuse 這類 observability 工具專門解決這個問題。
忽略版本差異:LangChain 的 API 每 3-6 個月大改一次,網路上超過半數教學都已過時——你照著寫會遇到 import 錯、方法不存在、行為改變。正確做法:(1) pip freeze 鎖定版本。(2) 只看官方文檔與 GitHub README,不看部落格舊教學。(3) 升級前先跑完整測試。
全用預設設定:chunk_size=1000、k=4、temperature=0.7 這些預設值是 LangChain 團隊用英文文件測出來的經驗值。你的場景是繁中 PDF、法律條文、程式碼——預設值幾乎鐵定不是最佳。拿 20 個真實測試問題,各調一組參數對比答案品質,花一天時間能把 RAG 準確率從 60% 推到 85%。
🏗️ 生產環境踩坑實錄
Token 成本爆量的真實案例:某團隊做客服 RAG,上線一週發現 OpenAI 帳單從預估的 USD 200 變成 USD 3,400。診斷後發現有個 Agent 會迴圈呼叫工具,每次都把完整對話歷史塞進去,token 爆量且無人察覺。監控做法:在 LLM 呼叫前後攔截計算 token,每日上傳到 Datadog/Grafana,單用戶/單對話設定 token 上限熔斷。
框架版本升級破壞既有 Chain:LangChain 0.1 → 0.2 時 LLMChain 被棄用改成 LCEL pipe 語法,大量舊 Chain 一升級就爆。處理策略:(1) requirements.txt 寫死版本(langchain==0.3.7)。(2) 升級在獨立分支做,跑完整回歸測試才合併。(3) 關注 GitHub changelog 的 breaking changes 段落,特別是 BREAKING 標籤。(4) 建立「黃金測試集」——20~50 個代表性問題,每次升級跑過一輪。
多租戶環境下的 API key 管理:SaaS 產品常見需求——每個客戶用自己的 OpenAI / Anthropic key。錯誤做法:把 key 寫進環境變數,結果所有租戶共用。正確做法:在請求層把 key 注入 LLM 實例(ChatOpenAI(api_key=tenant.key)),避免用 os.environ 全域污染;用 HashiCorp Vault 或 AWS Secrets Manager 集中管理,絕不寫進資料庫明文。
Retry 策略錯誤導致的無窮迴圈:LangChain 預設重試某些錯誤,如果你在外層又包一層 retry,兩者疊加會變成 25 次重試(5×5),rate limit 爆掉、雲端帳單爆掉、使用者等爆掉。正確做法:只在最外層做 retry、指數退避(1s, 2s, 4s)、最多 3 次,框架內層的 retry 關掉或設成 1 次。
向量資料庫失聯的 fallback 設計:Pinecone 當機 10 分鐘,你的 RAG 系統整個掛掉,客服電話爆。fallback 設計:(1) 健康檢查偵測到向量 DB 失聯時,切換到「純 LLM 無 context」模式,Prompt 告知使用者「知識庫暫時無法存取」。(2) 關鍵 FAQ 前 100 題的答案做離線快取,失聯時優先回答。(3) 本地保留一份 FAISS 副本當第二層備援。
❓ FAQ
LangChain 和 LlamaIndex 可以一起用嗎?
可以!常見搭配:LlamaIndex 負責資料載入和索引建構,LangChain 負責 Agent 邏輯和工具整合。兩者有官方整合,可以互相傳遞資料。
LangChain 跟 ChatGPT 的 GPTs 有什麼不同?
GPTs 是 OpenAI 提供的「無程式碼 Agent 建構工具」,你在網頁上貼 Prompt、上傳文件、勾選工具就能用,但只能跑在 ChatGPT 平台、只能用 OpenAI 模型、資料鎖在 OpenAI。LangChain 是你自己的程式碼,可以部署在自家伺服器、切換任意 LLM 供應商(OpenAI、Anthropic、本地開源模型)、完全控制資料流向。GPTs 適合原型驗證與個人工具,LangChain 適合正式產品。
不用框架可以做 AI 應用嗎?
完全可以,而且很多生產系統就是這樣做的。Claude 或 OpenAI 的官方 SDK 已經很好用,加上你自己寫的 retry、記憶管理、工具分派邏輯,幾百行 Python 就能跑得很穩。框架的價值不在於「做得到」而在於「做得快與做得標準」——如果你的團隊有 3 個以上工程師輪流維護這套程式,用框架的共通語言比看彼此手寫的亂碼好一百倍。單兵作戰或一次性專案,框架反而是負擔。
LangChain 的學習曲線很陡嗎?
是的,LangChain 的概念較多(Chain, Agent, Tool, Memory, Retriever…)。建議學習順序:1) 先學 API 直接呼叫 2) 再學基礎 Chain 3) 再學 RAG Chain 4) 最後學 Agent。
LangChain 效能問題怎麼解?
LangChain 被抱怨最多的就是「慢」,多半來自三個原因:(1) 過度抽象導致多餘呼叫——每個 Chain 節點都有 callback 與追蹤開銷,用 LCEL pipe 而非舊式 Chain 會快很多。(2) 同步等待——把 .invoke 改成 .ainvoke 走非同步,Chain 內可平行的步驟用 RunnableParallel 並行執行,通常能砍 30~50% 延遲。(3) Prompt 太長——每次都塞整個對話歷史會拖慢 LLM 回應,用 summary memory 或 window memory 壓縮上下文。
生產環境要用 LangChain 還是自己寫?
看團隊規模與迭代速度。建議用 LangChain 的情況:(1) 需要快速切換 LLM 供應商做 A/B 測試。(2) 多人協作需要共通抽象。(3) 需要現成的 MCP 整合、記憶管理、多 Agent 協作。建議自己寫的情況:(1) 流程非常固定、不會頻繁改動。(2) 效能是第一優先,毫秒級延遲敏感。(3) 團隊只有 1~2 人,維護框架升級的成本比自己寫還高。沒有標準答案,看痛點在哪。
Claude / Anthropic 官方 SDK 夠用嗎?
對很多場景來說夠用。Anthropic 的 Python SDK(anthropic 套件)已經內建 streaming、tool use、vision、prompt caching、batch API,加上最近推出的 Agent SDK 還提供了 MCP 整合與 session 管理,做單一模型的 Agent 已經相當完整。框架的價值主要在跨模型切換與複雜 Chain 組合——如果你確定只用 Claude、流程也不複雜,直接用官方 SDK 反而更乾淨。
LangGraph vs 單純用 function calling loop 的差異?
function calling loop 就是一個 while 迴圈——LLM 回傳 tool_call → 執行 → 把結果塞回 messages → 再給 LLM,直到模型輸出普通訊息為止,通常 30 行 Python 寫完。LangGraph 多出來的是:(1) 狀態可持久化(checkpoint),可以中斷後續跑。(2) 節點之間可以條件分支、可以並行、可以迴圈。(3) 可以插入 human-in-the-loop 節點要求人工審核。(4) 內建追蹤與可視化。簡單任務用 loop 就好,多 Agent 協作或需要暫停/續跑時用 LangGraph 才划算——細節可以看 AI Agent 實作教學。
有比 LangChain 更簡單的替代品嗎?
有。LlamaIndex 更簡單(如果你只做 RAG)。Haystack 也是不錯的替代品。如果只需要 Agent,LangGraph 或 CrewAI 更專注。如果需求很簡單,直接用 API 搭配自己的程式碼可能最好。