這篇文章是寫給「看完概念,想動手」的你。 如果你已經讀過 AI Agent 完全指南,理解什麼是 ReAct 迴圈、什麼是 Tool Use,接下來的問題就是:「好,那我到底要怎麼寫出一個 Agent?」這篇會帶你從零開始,用 Python + Claude API 寫出你的第一個能自主決策的 AI Agent——不靠框架,先理解原理,再用 LangChain 重寫比較差異。
🎯 讀完這篇你會得到
- 一個能跑的最簡 Agent(~50 行 Python)
- 一個進階版 3 步 Agent(搜尋 → 摘要 → 寄信)
- 同一個 Agent 的 LangChain 版本,方便你比較差異
- 常見踩坑清單 + 解法(無窮迴圈、token 爆量、JSON 壞掉)
⚡ 這篇在教什麼?(跟概念文的差異)
AI Agent 完全指南 講的是「什麼是 Agent、為什麼重要、有哪些流派」。那篇是地圖,這篇是施工手冊。
這篇不會重複的東西:
- Agent 的定義和歷史(→ 看概念文)
- Hermes Agent、OpenClaw、Claude Managed Agents 的深度介紹(→ 各自有專文)
- MCP 協議的運作機制(→ 有獨立教學)
這篇只做一件事:帶你寫程式。
你需要準備的工具
| 工具 | 用途 | 取得方式 |
|---|---|---|
| Python 3.10+ | 主要開發語言 | python.org |
| Claude API key | LLM 大腦 | console.anthropic.com |
anthropic Python SDK | 呼叫 Claude API | pip install anthropic |
| 文字編輯器 | 寫程式 | VS Code、Cursor 等 |
💡 本文用 Claude API 示範,但原理完全一樣適用於 OpenAI API。如果你手上只有 OpenAI key,把
anthropic換成openai,函式簽名微調即可。
先把環境裝好:
pip install anthropic
export ANTHROPIC_API_KEY="your-key-here" # macOS/Linux
# Windows: set ANTHROPIC_API_KEY=your-key-here🧠 Agent 的核心原理:其實就是一個 while 迴圈
在 AI Agent 完全指南 裡我們講過 ReAct(Reason + Act)迴圈。現在把它翻譯成程式碼,你會發現 Agent 的核心邏輯驚人地簡單:
虛擬碼版 Agent
def agent(task: str):
messages = [{"role": "user", "content": task}]
while True:
# 1. 把對話丟給 LLM,讓它「思考」
response = llm.chat(messages, tools=available_tools)
# 2. LLM 說「我要用工具」→ 執行工具
if response.wants_to_use_tool:
result = execute_tool(response.tool_name, response.tool_args)
messages.append(response) # 記錄 LLM 的決定
messages.append(tool_result(result)) # 記錄工具結果
# 3. LLM 說「我已經完成了」→ 回傳最終答案
else:
return response.text就這樣。整個 Agent 的核心就是一個 while 迴圈。
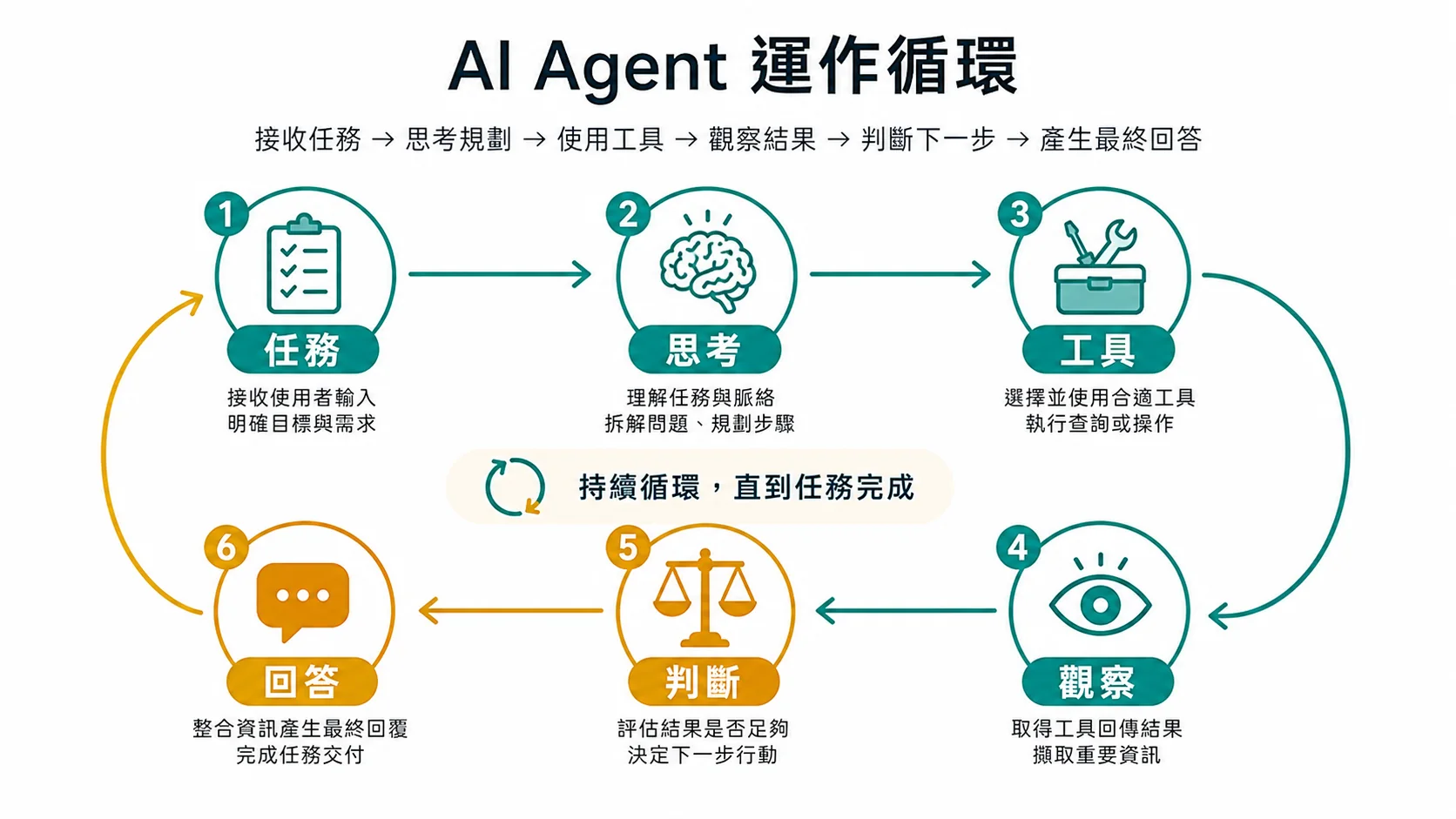
跟普通 API call 差在哪?
| 普通 API call | Agent | |
|---|---|---|
| 呼叫次數 | 1 次 | N 次(自動迴圈) |
| 誰決定下一步 | 你(開發者) | LLM 自己 |
| 工具使用 | 你硬編碼 | LLM 選擇要用哪個 |
| 結束條件 | 收到回應就結束 | LLM 判斷「任務完成」才結束 |
關鍵洞察:Agent 不是什麼黑魔法。它就是「讓 LLM 自己決定要不要呼叫工具、呼叫完再決定下一步」的迴圈。你寫普通 API call 的能力已經有了,只差「把它放進迴圈 + 給它工具」這一步。
圖解:ReAct 迴圈
使用者:「台北明天會下雨嗎?要不要帶傘?」
│
▼
┌─────────────────────────────────────┐
│ 🧠 LLM 思考:我需要查天氣資料 │
│ → 決定呼叫 get_weather("台北") │
└─────────────┬───────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 🔧 執行工具:get_weather("台北") │
│ → 回傳:明天降雨機率 85%,氣溫 22°C │
└─────────────┬───────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 🧠 LLM 再次思考:85% 很高,建議帶傘 │
│ → 沒有要再呼叫工具了,直接回答 │
└─────────────┬───────────────────────┘
│
▼
最終回答:「明天台北降雨機率 85%,建議帶傘。」這就是一個完整的 Agent 執行過程——兩次 LLM 呼叫、一次工具呼叫、自動判斷「夠了,可以回答了」。
🔨 實作一:最簡 Agent(不用框架,~50 行 Python)
目標
做一個能「查天氣 → 判斷要不要帶傘 → 回報結論」的 Agent。使用者只要說「台北明天要帶傘嗎?」,Agent 就會自己去查天氣、分析降雨機率、給出建議。
Step 1:定義工具(Function Calling schema)
Claude API 的 Function Calling 需要你用 JSON Schema 描述每個工具長什麼樣:
tools = [
{
"name": "get_weather",
"description": "查詢指定城市的天氣預報,包含溫度、降雨機率、天氣描述",
"input_schema": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名稱,例如:台北、東京、New York"
}
},
"required": ["city"]
}
}
]💡 重點:
description寫得越清楚,LLM 越能正確判斷「什麼時候該呼叫這個工具」。這不是寫給人看的,是寫給 LLM 看的。
Step 2:寫 Agent loop
import anthropic
import json
client = anthropic.Anthropic()
# 模擬天氣 API(實際專案換成真的 API)
def get_weather(city: str) -> dict:
"""模擬天氣查詢,實際應用請接 OpenWeatherMap 等 API"""
mock_data = {
"台北": {"temp": 22, "rain_prob": 85, "desc": "陰天有雨"},
"高雄": {"temp": 28, "rain_prob": 15, "desc": "晴天"},
}
data = mock_data.get(city, {"temp": 25, "rain_prob": 50, "desc": "多雲"})
return {"city": city, **data}
# 工具執行器:根據名稱呼叫對應函式
def execute_tool(name: str, args: dict) -> str:
if name == "get_weather":
result = get_weather(args["city"])
return json.dumps(result, ensure_ascii=False)
return json.dumps({"error": f"未知工具:{name}"})
def run_agent(user_task: str, max_steps: int = 5) -> str:
print(f"\n{'='*50}")
print(f"🚀 Agent 啟動:{user_task}")
print(f"{'='*50}\n")
messages = [{"role": "user", "content": user_task}]
system = "你是一個天氣助手 Agent。根據使用者的問題,使用工具查詢天氣,然後給出實用建議。"
for step in range(max_steps):
print(f"--- Step {step + 1} ---")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system=system,
tools=tools,
messages=messages,
)
# 檢查是否有 tool_use
if response.stop_reason == "tool_use":
# 找到 tool call
for block in response.content:
if block.type == "tool_use":
print(f"🔧 呼叫工具:{block.name}({block.input})")
result = execute_tool(block.name, block.input)
print(f"📦 工具回傳:{result}")
# 把 assistant 回應和 tool result 加進對話
messages.append({"role": "assistant", "content": response.content})
messages.append({
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
}],
})
break # 一次處理一個 tool call
elif response.stop_reason == "end_turn":
# LLM 認為任務完成,回傳最終答案
final = response.content[0].text
print(f"\n✅ Agent 完成:{final}")
return final
return "⚠️ 達到最大步數限制,Agent 停止。"Step 3:跑起來
if __name__ == "__main__":
answer = run_agent("台北明天會下雨嗎?我該帶傘嗎?")執行結果
==================================================
🚀 Agent 啟動:台北明天會下雨嗎?我該帶傘嗎?
==================================================
--- Step 1 ---
🔧 呼叫工具:get_weather({"city": "台北"})
📦 工具回傳:{"city": "台北", "temp": 22, "rain_prob": 85, "desc": "陰天有雨"}
--- Step 2 ---
✅ Agent 完成:台北明天的天氣預報是陰天有雨,降雨機率高達 85%,
氣溫約 22°C。強烈建議你帶傘出門!也可以多帶一件薄外套,
下雨天會比較涼。產出解析:Agent 是怎麼「自己決定」的?
注意看:你沒有寫任何 if/else 告訴它「收到天氣問題就呼叫 get_weather」。LLM 是自己讀了 tool description,理解「使用者在問天氣 → 我有一個查天氣的工具 → 我應該用它」。
這就是 Agent 跟傳統程式最大的差異:決策邏輯在 LLM 的大腦裡,不在你的 if/else 裡。
🚀 實作二:進階 3 步 Agent(搜尋 → 摘要 → 寄信)
上一個 Agent 只有一個工具。現在來做一個更接近真實場景的:給它三個工具,讓它自己決定呼叫順序。
目標
做一個能「搜尋最新 AI 新聞 → 用 AI 摘要重點 → 寄 email 給你」的多步驟 Agent。
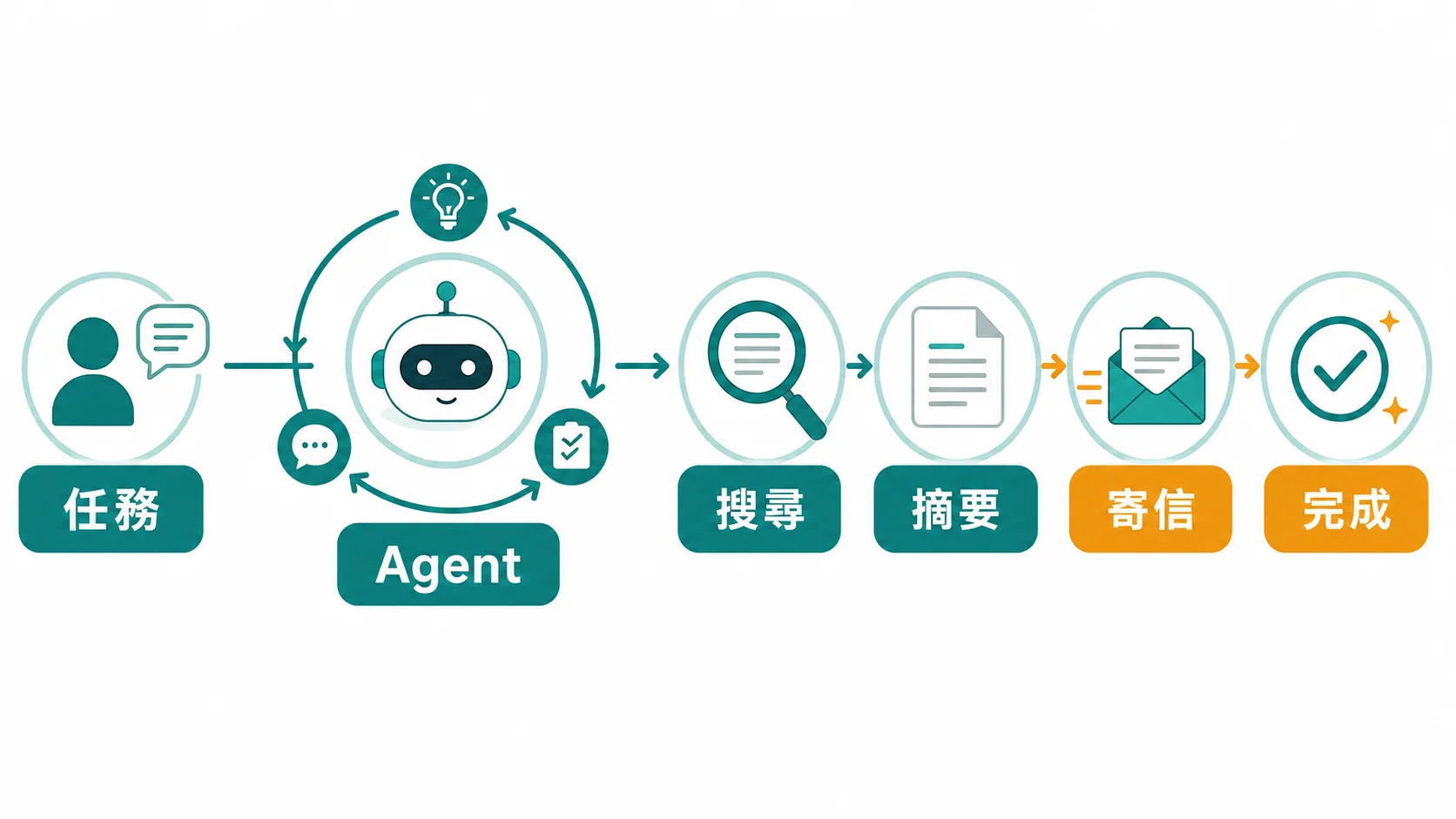
3 個工具定義
tools = [
{
"name": "search_news",
"description": "搜尋指定主題的最新新聞,回傳標題和內容摘要列表",
"input_schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜尋關鍵字,例如:AI Agent、LangChain"
},
"max_results": {
"type": "integer",
"description": "最多回傳幾筆結果,預設 3"
}
},
"required": ["query"]
}
},
{
"name": "summarize_text",
"description": "將一段長文字摘要成 3-5 個重點條列",
"input_schema": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "要摘要的原始文字"
}
},
"required": ["text"]
}
},
{
"name": "send_email",
"description": "寄送一封 email 到指定地址",
"input_schema": {
"type": "object",
"properties": {
"to": {
"type": "string",
"description": "收件人 email 地址"
},
"subject": {
"type": "string",
"description": "信件主旨"
},
"body": {
"type": "string",
"description": "信件內容(支援純文字)"
}
},
"required": ["to", "subject", "body"]
}
}
]Agent loop(帶 max_steps 和錯誤處理)
import anthropic
import json
from datetime import datetime
client = anthropic.Anthropic()
# === 模擬工具實作(正式環境替換成真的 API) ===
def search_news(query: str, max_results: int = 3) -> list:
"""模擬新聞搜尋"""
return [
{
"title": f"2026 年 AI Agent 市場規模突破 500 億美元",
"snippet": "根據最新報告,AI Agent 市場在 2026 年第一季成長 47%,"
"主要驅動力來自企業自動化需求和開源框架的成熟。"
},
{
"title": f"Anthropic 推出 Claude Managed Agents 正式版",
"snippet": "Anthropic 宣布 Claude Managed Agents 脫離 beta,"
"新增多 Agent 協作、自動 scaling、和企業級安全功能。"
},
{
"title": f"Hermes Agent 3.0 發布:支援自我進化和跨模型遷移",
"snippet": "開源社群打造的 Hermes Agent 推出 3.0 版,"
"新增 skill 自動學習和跨 LLM 遷移功能。"
},
]
def summarize_text(text: str) -> str:
"""模擬文字摘要(正式版可以再呼叫一次 LLM)"""
return (
"摘要重點:\n"
"1. AI Agent 市場 2026 Q1 成長 47%,規模突破 500 億美元\n"
"2. Anthropic Claude Managed Agents 正式脫離 beta\n"
"3. 開源 Hermes Agent 3.0 支援自我進化和跨模型遷移\n"
"4. 企業自動化需求是主要成長驅動力\n"
"5. 開源和商業方案正在快速收斂"
)
def send_email(to: str, subject: str, body: str) -> dict:
"""模擬寄信(正式版接 SendGrid / SES / SMTP)"""
print(f" 📧 寄信到 {to}")
print(f" 📧 主旨:{subject}")
return {"status": "sent", "to": to, "timestamp": datetime.now().isoformat()}
TOOL_MAP = {
"search_news": lambda args: json.dumps(
search_news(args["query"], args.get("max_results", 3)),
ensure_ascii=False
),
"summarize_text": lambda args: summarize_text(args["text"]),
"send_email": lambda args: json.dumps(
send_email(args["to"], args["subject"], args["body"]),
ensure_ascii=False
),
}
def run_multi_step_agent(user_task: str, max_steps: int = 10) -> str:
print(f"\n{'='*60}")
print(f"🚀 多步驟 Agent 啟動:{user_task}")
print(f"{'='*60}\n")
system = (
"你是一個新聞助手 Agent。你有三個工具:搜尋新聞、摘要文字、寄送 email。"
"請根據使用者需求,自主決定要用哪些工具、以什麼順序使用。"
"完成所有步驟後,回報最終結果。"
)
messages = [{"role": "user", "content": user_task}]
for step in range(max_steps):
print(f"--- Step {step + 1} ---")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=2048,
system=system,
tools=tools,
messages=messages,
)
if response.stop_reason == "tool_use":
# 處理所有 tool calls(Claude 可能一次要求多個)
tool_results = []
for block in response.content:
if block.type == "tool_use":
print(f"🔧 呼叫:{block.name}({json.dumps(block.input, ensure_ascii=False)[:80]}...)")
executor = TOOL_MAP.get(block.name)
if executor:
result = executor(block.input)
else:
result = json.dumps({"error": f"未知工具:{block.name}"})
print(f"📦 結果:{result[:100]}...")
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
elif response.stop_reason == "end_turn":
final = ""
for block in response.content:
if hasattr(block, "text"):
final += block.text
print(f"\n✅ Agent 完成(共 {step + 1} 步)")
print(f"📝 {final}")
return final
return "⚠️ 達到最大步數限制"
# 執行
if __name__ == "__main__":
run_multi_step_agent(
"幫我搜尋最新的 AI Agent 新聞,摘要重點,"
"然後寄到 [email protected]"
)執行 log 分析
============================================================
🚀 多步驟 Agent 啟動:幫我搜尋最新的 AI Agent 新聞,摘要重點,然後寄到 [email protected]
============================================================
--- Step 1 ---
🔧 呼叫:search_news({"query": "AI Agent 最新新聞"})
📦 結果:[{"title": "2026 年 AI Agent 市場規模突破 500 億美元", ...}]
--- Step 2 ---
🔧 呼叫:summarize_text({"text": "2026 年 AI Agent 市場規模..."})
📦 結果:摘要重點:1. AI Agent 市場 2026 Q1 成長 47%...
--- Step 3 ---
🔧 呼叫:send_email({"to": "[email protected]", "subject": "AI Agent 最新新聞摘要"})
📧 寄信到 [email protected]
📧 主旨:AI Agent 最新新聞摘要
📦 結果:{"status": "sent", "to": "[email protected]", ...}
--- Step 4 ---
✅ Agent 完成(共 4 步)注意看每一步 Agent 的「思考過程」:
- Step 1:使用者要搜尋新聞 → 呼叫
search_news - Step 2:拿到新聞 → 自己判斷要先摘要 → 呼叫
summarize_text - Step 3:摘要完成 → 寄信 → 呼叫
send_email - Step 4:全部做完了 → 回報結果
你沒有硬編碼任何執行順序。 Agent 自己決定了「搜尋 → 摘要 → 寄信」的順序。如果你的需求是「搜尋完直接寄信,不用摘要」,只要改 prompt,Agent 就會跳過摘要步驟。這就是 Agent 跟傳統 workflow 的根本差異。
🔄 用 LangChain 重寫同一個 Agent——差在哪?
上面我們手寫了大約 50-70 行的 Agent loop。現在用 LangChain 框架重寫同一個 Agent,看看差在哪。
LangChain 版本
# pip install langchain langchain-anthropic
from langchain_anthropic import ChatAnthropic
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
# 定義工具(用 @tool 裝飾器,比手寫 JSON Schema 簡潔)
@tool
def search_news(query: str, max_results: int = 3) -> str:
"""搜尋指定主題的最新新聞,回傳標題和內容摘要列表"""
# 同樣的模擬資料,省略...
return "AI Agent 市場 2026 Q1 成長 47%..."
@tool
def summarize_text(text: str) -> str:
"""將一段長文字摘要成 3-5 個重點條列"""
return "摘要重點:1. ..."
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""寄送一封 email 到指定地址"""
return f"已寄送到 {to}"
# 建立 Agent(一行搞定)
llm = ChatAnthropic(model="claude-sonnet-4-20250514")
agent = create_react_agent(llm, [search_news, summarize_text, send_email])
# 執行
result = agent.invoke({
"messages": [("user", "搜尋 AI Agent 新聞,摘要後寄到 [email protected]")]
})
for msg in result["messages"]:
print(msg.content)手寫 vs LangChain 比較
| 面向 | 手寫 Agent | LangChain 版 |
|---|---|---|
| 程式碼量 | ~70 行 | ~30 行 |
| 工具定義 | 手寫 JSON Schema | @tool 裝飾器自動產生 |
| Agent loop | 自己寫 while + 判斷 | create_react_agent 一行 |
| 可讀性 | 每一步都看得到 | 封裝後看不到內部 |
| 除錯難度 | 低(你寫的你知道) | 高(要翻框架原始碼) |
| 擴展性 | 手動加 memory、planning | 框架內建,裝插件 |
| 學習門檻 | 低(只要會 Python) | 中(要學框架 API) |
結論:什麼時候該用框架?
先手寫,再框架。 這是我的建議。
- 學習階段:手寫。你需要理解 Agent 的每一個步驟,才能在框架出問題時知道去哪裡 debug。
- 原型驗證:手寫。50 行就能跑,不需要學框架 API。
- 正式產品:用框架。你需要 memory、streaming、error recovery、multi-agent 這些框架已經幫你做好的功能。
- 團隊協作:用框架。統一的抽象層讓大家說同一種語言。
想深入 LangChain,可以看 LangChain / LlamaIndex 完整指南。
🚨 常見踩坑 & 解法
做了你的第一個 Agent 之後,你很快會遇到這些問題。以下是我自己和社群踩過最多的坑:
坑 1:Tool call 格式錯誤(模型回的 JSON 壞掉)
症狀:Agent 在某一步突然噴 json.JSONDecodeError,因為 LLM 回傳的 tool call 參數不是合法 JSON。
原因:小模型或 token 不夠時,LLM 可能回傳截斷的 JSON 或多加了 markdown 格式。
解法:
import json
def safe_parse_tool_args(raw_args):
"""安全解析工具參數,失敗時回傳 None 讓 Agent 重試"""
try:
if isinstance(raw_args, dict):
return raw_args # Claude API 通常已經解析好了
return json.loads(raw_args)
except json.JSONDecodeError:
# 嘗試清理常見問題:移除 markdown code fence
cleaned = raw_args.strip().strip("`").strip("json").strip()
try:
return json.loads(cleaned)
except json.JSONDecodeError:
return None # 讓 Agent 知道解析失敗,觸發重試💡 Claude API 的好消息:使用
tools參數時,Claude 回傳的tool_useblock 裡的input已經是解析好的 dict,不需要你自己 parse JSON。這個問題主要出現在用 OpenAI 的function_calling或開源模型時。
坑 2:無窮迴圈(Agent 不知道該停)
症狀:Agent 一直呼叫工具、一直呼叫工具,token 燒光了還沒停。
原因:system prompt 沒有告訴 LLM「什麼時候該停止」,或任務目標太模糊。
解法:
# 1. 一定要設 max_steps
def run_agent(task, max_steps=10): # 別設太大!
...
# 2. system prompt 要明確告訴 Agent 什麼時候該結束
system = """你是一個新聞助手。完成以下步驟後,直接回報結果:
1. 搜尋新聞
2. 摘要重點
3. 寄出 email
當 email 寄出成功後,回報「任務完成」並結束。
不要重複已經做過的步驟。"""
# 3. 偵測重複行為
last_tool_call = None
repeat_count = 0
for step in range(max_steps):
...
if current_tool_call == last_tool_call:
repeat_count += 1
if repeat_count >= 3:
print("⚠️ 偵測到重複行為,強制停止")
break坑 3:Token 爆量(每步都帶完整歷史)
症狀:Agent 跑 5-6 步之後,API 回傳 token limit exceeded 錯誤。
原因:每一步都把完整的對話歷史傳給 LLM,對話越來越長。
解法:
def trim_messages(messages, max_messages=20):
"""保留 system + 最近 N 輪對話"""
if len(messages) <= max_messages:
return messages
# 保留第一條(使用者的原始任務)和最近的對話
return [messages[0]] + messages[-(max_messages - 1):]進階做法是用「摘要壓縮」:每隔幾步讓 LLM 把前面的對話摘要成一段話,用摘要取代完整歷史。Hermes Agent 的記憶管理機制就是這個原理的進階版。
坑 4:小模型失敗率高
症狀:用便宜的小模型跑 Agent,工具呼叫經常出錯或邏輯不對。
原因:Agent 需要 LLM 同時做「理解任務 + 選對工具 + 組正確參數 + 判斷何時結束」,這對小模型來說太難了。
解法:
- 入門階段:用 Claude Sonnet 4 或 GPT-4o(性價比最佳)
- 正式產品:關鍵決策步驟用大模型,簡單步驟用小模型(混合策略)
- 開源模型:2026 年的 Qwen 3.6 和 Llama 4 已經有不錯的 tool calling 能力,但穩定性仍不如商業模型
想了解開源模型怎麼選,Hermes Agent 的 LLM 選型指南有很完整的分析。
🎯 下一步:你有三條路
做完這篇教學的兩個 Agent 之後,你已經理解了核心原理。接下來取決於你的需求:
路線 A:想自架開源 Agent
你想要完全掌控、不依賴任何商業 API、在自己的機器上跑。
- Hermes Agent 完整教學 — 會自我進化的個人 AI 助理,支援 skill 學習和跨模型遷移
- OpenClaw 指南 — 2026 年最火的開源 Agent 框架,GitHub 星標破紀錄
- MCP 協議入門 — Agent 連接工具的統一標準,不管用哪個框架都需要懂
路線 B:企業要導入 Agent
你是技術主管或決策者,要在公司內部部署 Agent。
- Claude Managed Agents — Anthropic 的全託管企業方案,不用管基礎建設
- 企業 AI Agent 導入指南 — 從評估到落地的完整 playbook
- AI API 串接指南 — 把 Agent 整合進現有系統
路線 C:想深入框架和協議
你想成為 Agent 開發專家,深入理解底層架構。
- LangChain / LlamaIndex 指南 — 最主流的 Agent 開發框架
- MCP 協議深入 — 理解 Agent 工具標準化的底層設計
- AI Agent 生態系 — 2026 年完整的 Agent 技術全景
❓ FAQ
不會 Python 能做 Agent 嗎?
可以,但學習路線不同。如果完全不會寫程式,可以用 No-Code AI 工具 來建立 Agent,例如 Zapier、Make、Dify 等平台都有 Agent 功能。但如果你想真正理解 Agent 的運作原理、做客製化開發,Python 幾乎是必備技能。好消息是你不需要是 Python 高手——本文用到的語法(函式、字典、迴圈)大約是入門等級的知識。
用 OpenAI API 還是 Claude API?
兩者都能做 Agent,核心原理完全相同。差異在於:Claude API 的 tool_use 回傳的是已解析的 dict,開發體驗更順暢;OpenAI 的 function_calling 歷史更久,社群範例更多。本文用 Claude API 示範是因為它的工具呼叫穩定性在 2026 年的評測中表現最佳,但你可以無痛切換——只需要改 client 初始化和 response 解析的部分。如果你已經在用 Claude Managed Agents,那 Claude API 是自然的選擇。
Agent 會不會亂花我的 API 錢?
會,如果你不設防護措施的話。每一步 Agent 迴圈都是一次 API 呼叫(加上完整的對話歷史),token 用量會指數成長。防護三招:(1)一定要設 max_steps,建議從 5-10 開始;(2)用 trim_messages 控制歷史長度;(3)開發階段用便宜的模型(Sonnet 而非 Opus)。實際成本參考:一個 3 步的 Agent(搜尋 → 摘要 → 寄信)大約消耗 3,000-5,000 tokens,以 Claude Sonnet 的定價約 0.01-0.02 美元。
開源模型能做 Agent 嗎?
2026 年的開源模型已經有基本的 Agent 能力了。Qwen 3.6、Llama 4、Mistral Large 都支援 function calling。但坦白說,穩定性和複雜推理能力還是不如 Claude 和 GPT-4o。如果你想用開源模型自架 Agent,推薦看 Hermes Agent——它的架構設計就是為了在開源模型上也能穩定運行,有很多針對小模型的 fallback 機制。
Agent 跟 RAG 差在哪?
RAG(Retrieval-Augmented Generation)是「先搜尋資料,再回答問題」,本質上是一次性的查詢流程。Agent 是「自主決定要做什麼、用什麼工具、做幾步」,是一個持續的決策迴圈。RAG 可以是 Agent 的其中一個工具——Agent 決定「我需要查資料」時,呼叫 RAG 工具去搜尋向量資料庫。換句話說,RAG 是「工具」,Agent 是「會用工具的大腦」。更完整的比較可以看 AI Agent 完全指南的架構章節。
做一個 Agent 大概要花多少時間?
取決於複雜度。本文的「最簡 Agent」從零開始大約 30 分鐘就能跑起來(前提是你已經有 Python 環境和 API key)。進階的 3 步 Agent 大約 1-2 小時。如果是正式產品等級(加上錯誤處理、日誌、monitoring、部署),預估 1-2 週。如果你不想從零開始,OpenClaw 和 Hermes Agent 都有完整的腳手架,可以大幅縮短開發時間。
多個 Agent 可以協作嗎?
可以,這叫 Multi-Agent 架構。一個 Agent 負責搜尋、一個負責分析、一個負責執行——彼此透過訊息傳遞協作。但這是進階主題,建議先把單一 Agent 做好再進階。想了解 Multi-Agent 的實作,可以看 AI Agent 生態系 裡的 Multi-Agent 章節,或直接用 Claude Managed Agents 的多 Agent 協作功能。
📌 一句話總結
Agent 的核心不是框架、不是模型、不是工具——是那個 while 迴圈。 理解「觀察 → 思考 → 行動 → 重複」的本質之後,不管你用 Claude、OpenAI、LangChain、還是自己手寫,都只是語法差異而已。先跑起來,再慢慢迭代。