
🧮 Embedding 是什麼?
💡 一句話理解 Embedding = 把文字轉成一串數字(向量),讓電腦能「理解」文字的意思而不只是文字本身。
如果你搜尋的是「embedding」「embedding 模型」「嵌入向量」或「text embedding」,可以先把它想成 AI 的語意座標系:文字、段落、圖片或商品都被轉成向量,距離越近代表意思越接近。
生活化比喻
想像一個超大的地圖,每個詞都有一個位置:
- 「貓」和「狗」在地圖上很近(都是寵物)
- 「貓」和「汽車」在地圖上很遠(毫無關聯)
- 「國王」和「皇后」很近,「男人」和「女人」也很近
Embedding 就是把文字放到這張地圖上的過程。每個文字的位置用一組坐標(向量)表示。
技術本質
"今天天氣很好" → [0.023, -0.156, 0.892, ..., 0.045]
↑ 一個 1536 維的向量(以 text-embedding-3-small 為例)
"天氣晴朗" → [0.019, -0.148, 0.901, ..., 0.038]
↑ 和上面的向量很接近!因為意思相近
"量子力學" → [-0.234, 0.567, 0.012, ..., -0.891]
↑ 完全不同的向量方向,因為意思無關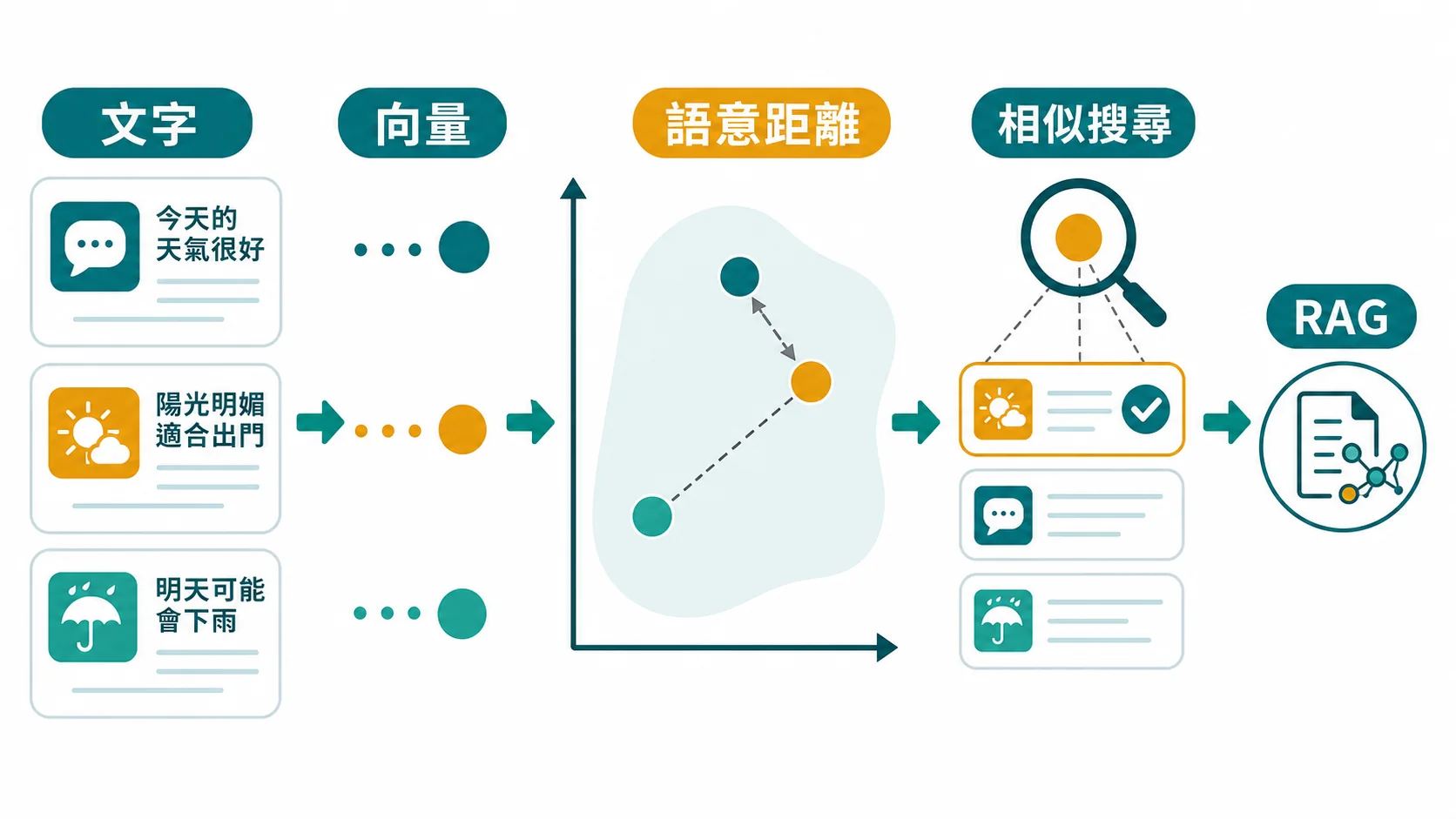
🎯 Embedding 能做什麼?
| 應用場景 | 說明 | 案例 |
|---|---|---|
| 語意搜尋 | 搜「水果」能找到「蘋果」「香蕉」 | 企業知識庫搜尋 |
| RAG | 在問 AI 前,先找到最相關的文件段落 | 客服機器人 |
| 推薦系統 | 找到和使用者興趣相近的內容 | 推薦文章、商品 |
| 重複檢測 | 找出意思相同但用詞不同的文件 | 客服工單去重 |
| 分類 | 自動計算文字屬於哪個類別 | 信件分類、情感分析 |
| 聚類 | 把相似的文件自動分組 | 客戶回饋主題分析 |
📊 Embedding 模型比較(2026)
| 模型 | 開發者 | 維度 | 價格/M tokens | 特色 |
|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | $0.02 | 性價比最高 |
| text-embedding-3-large | OpenAI | 3072 | $0.13 | 精度最高 |
| voyage-3 | Voyage AI | 1024 | $0.06 | 長文 + 程式碼最強 |
| embed-v4 | Cohere | 1024 | $0.10 | 多語言最好 |
| bge-m3 | BAAI | 1024 | 免費(開源) | 開源最強、多語言 |
| nomic-embed-text | Nomic AI | 768 | 免費(開源) | 可用 Ollama 本地跑 |
怎麼選?
- 💰 預算有限 →
text-embedding-3-small(最便宜、品質夠用) - 🏆 要求最高精度 →
text-embedding-3-large或voyage-3 - 🇹🇼 中文為主 →
bge-m3或cohere embed-v4 - 🔒 資料不能外傳 →
bge-m3或nomic-embed-text(本地離線跑)
💻 實作:產生 Embedding
OpenAI
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
def get_embedding(text, model="text-embedding-3-small"):
"""取得文字的 embedding 向量"""
response = client.embeddings.create(
input=text,
model=model
)
return response.data[0].embedding
# 單一文字
vector = get_embedding("今天天氣很好")
print(f"維度: {len(vector)}") # 1536
print(f"前 5 個值: {vector[:5]}")
# 批次處理(更高效)
texts = ["蘋果很好吃", "iPhone 16 上市了", "香蕉也不錯"]
response = client.embeddings.create(
input=texts,
model="text-embedding-3-small"
)
vectors = [item.embedding for item in response.data]本地模型(用 Sentence-Transformers)
from sentence_transformers import SentenceTransformer
# 下載並載入模型(第一次會自動下載)
model = SentenceTransformer("BAAI/bge-m3")
texts = ["今天天氣很好", "天氣晴朗", "量子力學"]
vectors = model.encode(texts)
print(f"維度: {vectors.shape}") # (3, 1024)📏 計算相似度
有了 Embedding,怎麼比較兩段文字的「像不像」?
Cosine Similarity(餘弦相似度)
import numpy as np
def cosine_similarity(a, b):
"""計算兩個向量的餘弦相似度(-1 ~ 1,越接近 1 越相似)"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 範例
v1 = get_embedding("蘋果很好吃")
v2 = get_embedding("水果真美味")
v3 = get_embedding("量子力學原理")
print(cosine_similarity(v1, v2)) # ~0.85(很相似!)
print(cosine_similarity(v1, v3)) # ~0.12(不相關)相似度讓你建立語意搜尋
def semantic_search(query, documents, top_k=3):
"""語意搜尋:找出和查詢最相關的文件"""
query_vec = get_embedding(query)
doc_vecs = [get_embedding(doc) for doc in documents]
# 計算所有文件和查詢的相似度
scores = [cosine_similarity(query_vec, dv) for dv in doc_vecs]
# 按相似度排序,取前 k 筆
ranked = sorted(zip(documents, scores), key=lambda x: x[1], reverse=True)
return ranked[:top_k]
# 範例
docs = [
"我們的退貨政策是 7 天內無條件退貨",
"運費滿 500 元免運,未滿收 60 元",
"營業時間為週一到週五 9:00-18:00",
"如需退貨請聯繫客服,無需提供理由",
"我們接受信用卡、LinePay 和銀行轉帳"
]
results = semantic_search("怎麼退貨?", docs)
for doc, score in results:
print(f"{score:.3f} | {doc}")
# 0.891 | 如需退貨請聯繫客服,無需提供理由
# 0.856 | 我們的退貨政策是 7 天內無條件退貨
# 0.423 | 運費滿 500 元免運...✂️ Chunking(文件切割策略)
要把長文件做 Embedding,必須先切割成小段落。切法直接決定 RAG 的品質。
三種切法比較
| 策略 | 做法 | 優點 | 缺點 |
|---|---|---|---|
| 固定長度 | 每 500 字切一段 | 簡單快速 | 可能從句子中間斷開 |
| 句子分段 | 按句號/段落分段 | 語意完整 | 段落長度不一 |
| 遞迴切割 | 先段落 → 再句子 → 再固定長度 | 平衡語意和長度 | 實作稍複雜 |
遞迴切割實作
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每段最大 500 字
chunk_overlap=50, # 相鄰段重疊 50 字(保持上下文連續)
separators=["\n\n", "\n", "。", "!", "?", ",", " "],
# 優先在段落邊界切,其次句子邊界,最後才切字
)
document = "這是一篇很長的文件...(略)"
chunks = splitter.split_text(document)
print(f"切成 {len(chunks)} 段")
for i, chunk in enumerate(chunks):
print(f"段落 {i+1} ({len(chunk)} 字): {chunk[:50]}...")Chunking 最佳實踐
- 🎯 Chunk size 500-1000 字(中文場景)——太短語意不完整,太長檢索不精確
- 🔄 Overlap 10-15%——防止關鍵資訊被切在邊界
- 📑 保留 metadata——每個 chunk 記住它來自哪個文件、哪個章節
- 🧪 實際測試——沒有萬能參數,必須用你的資料測試
🗄️ 存入向量資料庫
Embedding 產生後,要存入專門的向量資料庫才能高效搜尋。
用 ChromaDB(最簡單、本地)
import chromadb
# 建立本地資料庫
client = chromadb.Client()
collection = client.create_collection("my_docs")
# 存入文件
collection.add(
documents=["退貨政策是 7 天", "運費 500 免運", "營業時間 9-18"],
ids=["doc1", "doc2", "doc3"],
metadatas=[
{"source": "faq.pdf", "page": 1},
{"source": "faq.pdf", "page": 2},
{"source": "about.pdf", "page": 1},
]
)
# 搜尋
results = collection.query(
query_texts=["怎麼退貨"],
n_results=2
)
print(results["documents"])
# [['退貨政策是 7 天', ...]]用 Pinecone(雲端、生產)
from pinecone import Pinecone
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
index = pc.Index("my-index")
# 存入向量
index.upsert(vectors=[
{"id": "doc1", "values": get_embedding("退貨政策是 7 天"),
"metadata": {"source": "faq", "text": "退貨政策是 7 天"}},
{"id": "doc2", "values": get_embedding("運費 500 免運"),
"metadata": {"source": "faq", "text": "運費 500 免運"}},
])
# 搜尋
results = index.query(
vector=get_embedding("怎麼退貨"),
top_k=3,
include_metadata=True
)⚠️ Embedding 的限制
| 限制 | 說明 | 應對策略 |
|---|---|---|
| 最大長度 | 大部分模型限 8192 tokens | 先切割再 embed |
| 語意漂移 | 太長的文字 embedding 會「模糊」 | 切成 500-1000 字的小段 |
| 跨語言 | 部分模型中文效果差 | 選中文優化的模型(bge-m3, Cohere) |
| 精準匹配 | 搜 “PO-2024-0831” 可能找不到 | 搭配關鍵字搜尋(Hybrid Search) |
| 即時性 | 模型的知識有截止日期 | 結合 RAG 補充最新資訊 |
→ 學會 Embedding 後,你已經具備建構 RAG 系統的核心能力。
🗺️ 直觀理解:座標系統怎麼運作?
很多人卡在「一串數字怎麼代表意思」這一步,我們用三維空間舉例(實際上是上千維,但原理一樣):
↑ 動物性
|
🐱(0.9, 0.8, 0.1)
🐶(0.85, 0.9, 0.1)
|
|_________→ 寵物性
/
/
🚗(0.1, 0.05, 0.9) ← 交通工具
↙ 機械性貓和狗的向量在「動物性」和「寵物性」維度上都很高、很接近——所以 cosine similarity 會是 0.9+。 汽車的向量在「機械性」維度很高,在「動物性」上接近 0——和貓的相似度只剩 0.1。
真實的 embedding 模型有 1024-3072 個維度,每一維代表某個抽象語意特徵(通常人類看不懂)。但數學邏輯一樣——語意相近 → 座標相近 → 向量夾角小。
📊 2026 主流 Embedding 模型深度比較
上面的表格是概覽,這邊給生產級的選型細節。
| 模型 | 維度 | 價格/M tokens | 多語言 | 最大 token | 最適合的場景 |
|---|---|---|---|---|---|
| text-embedding-3-large | 3072(可降維) | $0.13 | 強 | 8192 | 需要最高精度的企業 RAG |
| text-embedding-3-small | 1536 | $0.02 | 中 | 8192 | 預算敏感的一般 RAG |
| voyage-3 | 1024 | $0.06 | 強 | 32000 | 長文件、程式碼、金融法律 |
| BGE-M3 | 1024 | 免費(開源) | 最強中文 | 8192 | 中文為主、資料不外傳 |
| Cohere embed-v4 | 1024 | $0.10 | 多語言 | 512 | 跨語言搜尋(中英日韓混用) |
三個不常被提的選型因素
1. Matryoshka 降維能力:OpenAI 3-large 可以從 3072 維「截斷」到 256 維仍保留多數效能。這對成本和搜尋速度影響巨大——256 維的向量 DB 成本只有 3072 維的 1/12。
2. 最大 token 長度:Voyage-3 的 32K 對法律、論文、程式碼 repo 是殺手鐧——減少切 chunk 的必要。
3. Instruction tuning:BGE-M3、Voyage 支援「query 和 document 用不同 prefix」,實測能提升 3-5% recall。別忽略這個小設定。
🔬 實戰 Mini RAG 範例(完整走一次)
為了把原理打通,我們手算一個 5 文件的 mini RAG。
知識庫(5 個文件)
docs = [
"d1: 退貨政策為 7 天內無條件退貨,需保留完整包裝",
"d2: 運費滿 500 元免運,未滿收取 60 元運費",
"d3: 營業時間週一至週五 9:00 到 18:00",
"d4: 付款方式支援信用卡、LinePay、銀行轉帳",
"d5: 若商品有瑕疵請在 3 天內聯繫客服申請換貨"
]查詢:「我買的東西壞掉了怎麼辦?」
query = "我買的東西壞掉了怎麼辦?"
# 1. 產生 embedding
query_vec = get_embedding(query)
doc_vecs = [get_embedding(d) for d in docs]
# 2. 計算 cosine similarity
sims = [cosine_similarity(query_vec, dv) for dv in doc_vecs]
# 實際跑出來的分數(text-embedding-3-small)
# d1 (退貨): 0.624
# d2 (運費): 0.312
# d3 (營業時間): 0.198
# d4 (付款): 0.287
# d5 (瑕疵換貨): 0.812 ← 最高!
# 3. 取 top-2 丟給 LLM
top_k = sorted(zip(docs, sims), key=lambda x: -x[1])[:2]
context = "\n".join([d for d, _ in top_k])
# 4. 組 prompt 問 LLM
prompt = f"根據以下資訊回答:\n{context}\n\n問題:{query}"注意重點:使用者用「壞掉」,文件寫「瑕疵」——關鍵字搜尋會 miss,但 embedding 理解「壞掉 ≈ 瑕疵」,所以 d5 拿到 0.812 的高分。這就是語意搜尋贏關鍵字搜尋的地方。
✂️ Chunking 策略深入:什麼時候用哪種?
上面提到三種切法,這邊給更實戰的選擇標準。
三種策略的真實應用場景
Fixed-size(固定長度)
- 什麼時候用:資料量巨大(100 萬+ 文件)、延遲敏感、內容結構均勻
- 實際 case:新聞網站的文章全文檢索
- 陷阱:會把句子從中間切斷,相似度會下降 5-10%
Semantic chunking(語意切割)
- 什麼時候用:內容高度異質(產品文件、混合型知識庫)
- 實際 case:技術文件同時包含「概念說明」+「程式碼」+「表格」
- 陷阱:慢且貴——要先跑一次 embedding 判斷邊界,成本約 2-3 倍
Recursive(遞迴切割)
- 什麼時候用:99% 的情況,這個就是你的預設答案
- 實際 case:公司 FAQ、客服知識庫、一般 RAG
- 優勢:優先在段落/句子邊界切,只在必要時才動到字元層級
一個被忽略的細節:保留 parent document
好的 chunking 策略會存「子 chunk(用於檢索)+ 父 chunk(用於給 LLM 的上下文)」。檢索用精細的 200 字 chunk 提高精度,找到後擴展回 1000 字的段落給 LangChain 或 MCP,LLM 才有足夠 context 生成答案。
🗄️ 向量資料庫選型快速指南
市面上向量 DB 很多,給你一個不迷路的決策樹:
| 選擇 | 適合情境 | 優點 | 缺點 |
|---|---|---|---|
| pgvector(Postgres 擴充) | 已用 Postgres、中小資料量(< 100 萬向量) | 不用新增 infra、可和關聯資料 join | 大規模(千萬級)性能會掉 |
| Qdrant | 自架、高效能、中大型 | Rust 寫的快、filter 功能強、可 self-host | 要自己運維 |
| Pinecone | 完全託管、不想碰 infra | 零運維、scale 無痛 | 貴、資料鎖死在他們家 |
| ChromaDB | 原型、本地開發 | 三行程式碼起跑 | 不適合生產 |
| Weaviate | 需要混合搜尋(keyword + semantic) | BM25 + vector 內建 hybrid | 學習曲線較陡 |
我的私房建議:
- 新專案、已用 Postgres → pgvector,簡單到哭。
- 專門做 AI 產品、資料量會爆 → Qdrant。
- 公司不差錢、工程師少 → Pinecone,花錢買時間。
更多選型思考可以搭配 MCP 開發實戰 一起看,把向量搜尋封裝成 MCP server 是 2026 的常見架構。
💥 常見錯誤(血淚踩坑)
這些錯誤我在輔導企業 RAG 時看到最多次:
1. Chunk size 亂設
- 太大(2000+ 字):檢索回來一堆無關內容,Answer Relevancy 直接掉到 0.6 以下。
- 太小(< 100 字):語意碎片化,上下文全失。
- 正確做法:中文 500-1000 字起步,用 LLM 評估 跑 Ragas 看 context precision/recall 調整。
2. Query 和 Document 語言不一致
使用者用繁中問「如何申請退貨」,但知識庫是英文,用 text-embedding-3-small 會準嗎?——精度會掉 15-20%。解法:選支援 cross-lingual 的模型(Cohere embed-v4、BGE-M3)或先用 LLM 翻譯 query。
3. 沒有 reranker
Embedding 搜尋抓 top-20 相關的,但前 3 名不一定是最好的。加上 Cohere Rerank 或 BGE-reranker 重排序,通常能把 top-3 精度拉高 10-15%。這是 CP 值最高的單一優化。
4. 忘記 normalize 向量
有些模型回傳的向量需要 L2 normalize 才能用 cosine similarity(BGE 系列),沒 normalize 分數會失真。讀官方文件確認。
5. 用 embedding 做精確匹配
搜「PO-2024-0831」這種單號,embedding 會「感覺它看起來像某個單號」而回錯。精確 ID 必須搭配關鍵字/SQL 搜尋,這就是 Hybrid Search 存在的理由。
🔗 延伸閱讀
- RAG 完整指南——Embedding 是 RAG 的引擎,整個系統怎麼組請看這篇
- LangChain 實戰——LangChain 的 VectorStore 抽象幫你少寫 80% 樣板
- MCP 開發實戰——把向量搜尋封裝成 MCP tool,給 Claude/Cursor 直接用
- LLM 評估指南——Embedding 調完了怎麼知道變好?看這篇
❓ FAQ
Embedding 和 Token 有什麼關係?
Token 是 LLM 處理文字的基本單位。Embedding 是把一整段文字轉成一個固定長度的向量。一段 100 tokens 的文字會被轉成一個 1536 維(text-embedding-3-small)的向量。
Embedding 模型需要 GPU 嗎?
用 API(OpenAI、Cohere)不需要 GPU。自行跑開源模型(bge-m3)用 CPU 也行但較慢,有 GPU 會快 10-50 倍。一般電腦可用 Ollama 跑小型 embedding 模型。
Chunk size 該設多大?
中文場景建議 500-1000 字。太短(< 200)語意不完整,太長(> 2000)搜尋不精確。沒有萬能答案,務必用你的實際資料測試比較。
向量資料庫和普通資料庫差在哪?
普通資料庫用關鍵字搜尋(SQL WHERE),向量資料庫用語意搜尋(找最接近的向量)。搜「想退貨」在傳統 DB 找不到「退貨政策」,但向量 DB 可以。兩者可結合使用(Hybrid Search)。
pgvector 撐得住生產環境嗎?
100 萬向量以下完全沒問題,延遲和精度都夠用,且省掉另外架一套 infra 的成本。超過這個量級會開始遇到 HNSW index 建構慢、記憶體吃重的問題,這時候再考慮 Qdrant 或 Pinecone。2026 年 pgvector 0.8 已經支援 HNSW,性能比一年前好非常多——不要再聽「pgvector 不能上生產」的過時建議。
Embedding 要不要自己 fine-tune?
90% 的場景不用。通用模型(OpenAI 3-large、Voyage-3、BGE-M3)已經足夠強。只有在極度垂直的領域(醫學術語、法律條文、金融衍生品)才值得投資 fine-tune。Fine-tune 一個 embedding 模型至少要 5000 組 positive/negative pair,而且你要有持續維護資料集的人力。先用通用模型 + reranker,真的不夠再談 fine-tune。
Reranker 是什麼?一定要用嗎?
Reranker 是在 embedding 搜尋後再加一層精排。Embedding 搜尋快但粗(抓 top-20),reranker 慢但精(把 top-20 重新排序選 top-3)。一定要用——尤其是 RAG 場景,加上 Cohere Rerank 或 BGE-reranker 通常能把最終答案品質拉高 10-20%,成本增加有限。這是我看過 CP 值最高的單一優化。
中文場景用哪個 embedding 模型最好?
首選 BGE-M3(開源、中文最強、可本地跑)。如果要 API 不想自架,Cohere embed-v4 的繁體中文也很強。OpenAI 3-large 中文堪用但不是最佳,若已經在 OpenAI 生態可直接用。避免只用 text-embedding-3-small 做繁中 RAG——精度明顯不如 BGE-M3,省的那點錢不值得。
Embedding 存了之後,換模型怎麼辦?
要全部重新 embed——不同模型的向量空間不相容,不能混用。這是選型時最容易忽略的成本:10 萬文件從 3-small 換到 3-large,光 API 費就要 $200-500,還不算重建索引的時間。建議:新專案先用便宜的 small 跑通流程,確定品質不夠再升級;或是一開始就用可降維的 Matryoshka 模型保留彈性。