Token 是什麼?AI token 中文意思先講清楚
Token 是 AI 讀懂文字用的「最小積木」。 你打一句話給 AI,AI 會先把這句話切成一塊塊的 token,再逐塊讀進去處理、逐塊吐出答案。每切一塊、每產出一塊,都會算錢——這就是為什麼 token 這兩個字你天天聽到。
具體長什麼樣?舉三個例子:
- 英文:
"Hello world"被切成 2 個 token - 中文:「你好世界」被切成 6 個 token(大多數漢字是 1 個 token)
- 日文:「こんにちは」(你好)被切成 8 個 token
能看懂這三個例子,就有了「理解 AI 計費、AI 記憶限制、AI 為什麼會忘記」的基礎。這篇把 token 從零講到能和工程師對話,並附一個貼字就能看 token 怎麼切的互動工具。
Token 這個字,2026 年最常在公開場合講的人是黃仁勳。NVIDIA CEO 在 GTC 2026 主題演講中提到 token 超過 70 次,把資料中心重新定義為「AI 工廠」(AI Factory)——工廠的產品就是 token。
如果你想理解「為什麼 NVIDIA 股價能撐住」「為什麼 OpenAI 要融資千億」「為什麼 Claude / GPT 會收費」——一切答案都在 token。
🏆 懶人包
- Token = AI 處理語言的最小單位,不是字、不是詞,而是 tokenizer 切出來的碎片
- 一個英文字 ≈ 1.3 token;一個中文字 ≈ 1 token;「人工智慧正在改變世界」= 9 tokens
- 黃仁勳:Token 是AI 的新貨幣,資料中心是token 工廠,revenue = tokens/watt × gigawatts
- 每家模型的 context window 和 token 單價差異大——Claude Opus 4.7 是 $5/$25 每 M,DeepSeek V4 是 $0.28/$0.42
- 2027 年前全球 token 需求 > 1 兆美元(黃仁勳 GTC 2026 預測)
🏭 從 GTC 2026 談起:為什麼黃仁勳把 token 講了 70 次?
2026 年 3 月 GTC 主題演講,黃仁勳把他的世界觀濃縮成一句話:
「Data centers have been replaced by AI Factories. The product of an AI factory is the token.」
(資料中心已被 AI 工廠取代。AI 工廠的產品是 token。)
他提了一個 token 經濟的公式:
Revenue = (Tokens per Watt) × (Available Gigawatts)
白話:「每瓦電能產多少 token」× 「你有多少瓦電」= AI 公司的營收。NVIDIA 賣的不只是晶片,是「把電變成 token 的機器」。
他還提到幾個震撼點:
- Silicon Valley 招募工程師時,薪水之外會附 token 額度——「How many tokens come with my job?」成為面試問題
- 2027 年前全球 token 運算需求 超過 1 兆美元
- 過去兩年運算需求成長 100 萬倍
- 推理時代來臨(Inference Inflection)——reasoning token 消耗是傳統 chat 的 100 倍
🧭 為什麼你該在乎? 當 NVIDIA 的 CEO 把 token 當成一個新產業類別在講,下游所有人(雲端、軟體、AI 應用、職場)都會被波及。理解 token 不再只是技術知識,是理解 2026 年產業語境的基礎詞彙。
💹 這和 NVIDIA 股價有什麼關係?(給投資人看的一段)
如果你是從股市新聞循線點進來的讀者——這一段是給你的。不給買賣建議,只解釋商業邏輯,讓你判斷黃仁勳的話該用多少折扣率看。
為什麼黃仁勳一直提 token?
這是產業敘事升級:
- 舊敘事:NVIDIA 賣 GPU——景氣循環產業,挖礦榮景過後市場怕它變 Intel
- 新敘事:NVIDIA 賣 token 生產力——基礎建設公司,類比電力公司、石油公司,本益比可以撐在高位
當敘事從「硬體週期股」換成「AI 經濟的基礎產能」,本益比可接受的區間從 20 倍拉到 40–50 倍。這就是為什麼黃仁勳每次演講都要把 token 講成新貨幣——這個字能否成為業界共識,直接影響 NVIDIA 幾千億美元的市值。
Revenue = Tokens/Watt × Gigawatts 的股票含義
黃仁勳提出的這個公式拆開看:
| 變數 | 誰影響 | 對 NVIDIA 有利的方向 |
|---|---|---|
| Tokens / Watt(每瓦 token 產量) | NVIDIA 的 GPU 設計 | Blackwell → Rubin 每代提升 3–5 倍 |
| Available Gigawatts(總電力) | 客戶蓋的資料中心規模 | 客戶越蓋越大 → 買更多 GPU |
兩個乘數都在往對 NVIDIA 有利的方向跑。這就是為什麼他要把營收公式寫成乘法而不是加法——乘法意味著兩端都還有成長空間。
「2027 年前 token 需求破 1 兆美元」怎麼讀?
黃仁勳在 GTC 2026 的這個預測,是 NVIDIA 自家的市場預測,不是中立第三方數字。解讀時要留意:
- ✅ 合理部分:推理時代(Inference Inflection)確實會大幅放大 token 消耗,reasoning token 比 chat 貴 10–100 倍是事實
- ⚠️ 需折扣的部分:這個數字含有 NVIDIA 自身股東敘事成分,類似「石油公司 CEO 說全球能源需求翻倍」——方向可能對,幅度要打問號
- 🎯 可驗證的中期指標:看 Microsoft / Google / Meta / Amazon 四家 2026–2027 資本支出實際數字。這些才是真正買單者
誰受益、誰挑戰?
Token 經濟的產業鏈傳導(純粹商業邏輯整理,不是推薦):
| 環節 | 代表公司 | 敘事 |
|---|---|---|
| 🏗️ 晶片設計 | NVIDIA、AMD | 直接受益,但估值已反映大量預期 |
| 💾 HBM 記憶體 | SK Hynix、Samsung、Micron | Token 運算吃記憶體頻寬,供應緊張 |
| 🔥 散熱 / 先進封裝 | TSMC 的 CoWoS、Broadcom、Marvell | Blackwell / Rubin 熱密度極高 |
| ⚡ 電力 / 能源 | 核能復興股、小型模組反應爐 | 黃仁勳點名的「token 工廠缺電」 |
| 🌐 雲端超大規模業者 | Microsoft、Google、Amazon、Meta | 花最多錢買 GPU,但也壟斷終端需求 |
| 💻 AI 應用 / 模型商 | OpenAI、Anthropic | 能不能把「買 token 成本」轉嫁給消費者是關鍵 |
⚠️ 投資免責聲明 本站不提供投資建議。以上產業鏈分析純屬商業邏輯整理,不構成任何買賣推薦。實際投資決策請諮詢合格理財顧問,並充分考量自身風險承受度。
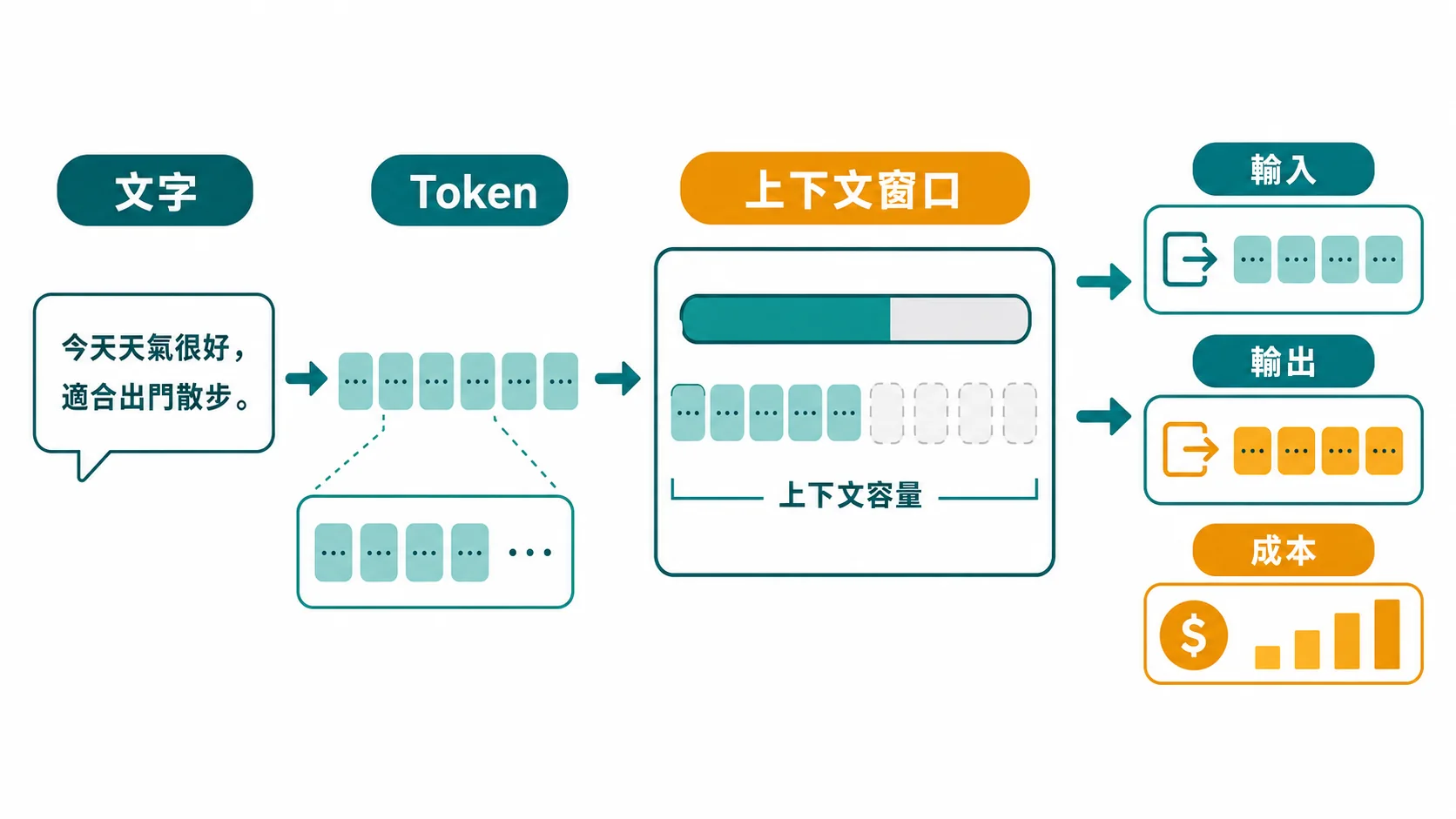
Token 是什麼?先看它長什麼樣
Token 是 AI 處理語言的最小單位。 你可以把它想成 AI 的「文字積木」——但 token ≠ 字。
用下面這個互動工具親眼看一下(試著貼入你自己的文字):
🧮 Token 視覺化工具
貼文字進去,看每個字被切成幾個 token。 100% 準確對應 GPT-4 / GPT-4o / GPT-5 系列; Claude / Gemini / DeepSeek 為近似值(實際需呼叫 API)。
觀察重點
- 英文常用字 = 1 個 token:
hello、world、the各是 1 個 token - 英文複合詞被拆:
tokenization被拆成token+ization - 中文每個字 ≈ 1 個 token:漢字資訊密度高,但 tokenizer 給每個字獨立 token
- 日文最吃 token:平假名 / 片假名把情況拉更差
- 切換 tokenizer 看差異:cl100k_base(GPT-4 時代)和 o200k_base(GPT-4o / GPT-5)對 CJK 有明顯差距
各語言 token 消耗實測對照
以「人工智慧正在改變世界」為例,不同語言的 token 消耗差異明顯:
| 語言 | 文字 | Token(o200k_base) |
|---|---|---|
| 中文 | 人工智慧正在改變世界 | 9 tokens |
| 日文 | 人工知能が世界を変えている | 10 tokens |
| 韓文 | 인공지능이 세상을 바꾸고 있다 | ~14 tokens |
| 英文 | AI is changing the world | 5 tokens |
| 西班牙文 | La IA está cambiando el mundo | 7 tokens |
想深入了解哪種語言吃更多 token、各廠牌 tokenizer 的差異,請看 中文比英文省 token?實測破除最常見的 CJK tokenizer 迷思。
📦 上下文窗口(Context Window):AI 一次能「記住」多少 token
上下文窗口 是 AI 單次對話能處理的 token 數量上限。想像 AI 的腦袋是一張桌子——你們的整段對話(提問 + 回答 + 附加的文件)都必須放在這張桌子上。桌子滿了,最早的東西就會被擠掉。
2026 主流模型的 context window
| 模型 | Context | 中文字容量 | 對應規模 |
|---|---|---|---|
| GPT-4o | 128K | ~12 萬字 | 一本中篇小說 |
| Claude Sonnet 4.6 | 200K | ~20 萬字 | 兩本書 |
| Gemini 3 Pro | 1M | ~100 萬字 | 一整套哈利波特 |
| Claude Opus 4.7 | 1M | ~85 萬字 | 3–4 本書 |
| DeepSeek V4 | 128K | ~12 萬字 | 一本中篇小說 |
💡 1M context 實際上能做什麼? 「把整份 100 頁合約丟進去問問題」、「把整個 GitHub repo 給 AI 做 code review」、「把一本書摘要成 3 頁」——這些都是 1M context 時代才能做到的。
🔢 Token 怎麼收費?2026 年主流模型比較
每家的 token 單價 + 消耗速度共同決定你的帳單。下表按中文場景下「每百萬 token」的輸入/輸出單價排序:
| 模型 | 輸入($/M) | 輸出($/M) | 中文效率(vs 英文) |
|---|---|---|---|
| DeepSeek V4 | $0.28 | $0.42 | 🥇 中文專門優化,接近 1.0x |
| Qwen-Max | ~$0.5 | ~$2 | 🥇 中文專門優化 |
| Gemini 3 Pro | $2 | $12 | 🥈 |
| GPT-4o | $2.50 | $10 | 🥈 |
| GPT-5.4 | $2.50 | $15 | 🥈 |
| Claude Sonnet 4.6 | $3 | $15 | 🥈 |
| Claude Opus 4.7 | $5 | $25 | 🥉(新 tokenizer 對 CJK 較差) |
輸出 token 為什麼比輸入貴 3–5 倍? 因為 AI 生成 token 時需要逐個計算下一個詞的機率分布,GPU 負載遠高於「讀取」輸入。
💰 Token 成本對日常情境的換算
常見任務消耗表
以 GPT-4o($2.50/$10)為例:
| 任務類型 | 輸入 Token | 輸出 Token | 實際成本 |
|---|---|---|---|
| 問一個簡單問題(100 字) | 50 | 150 | $0.0016 ≈ 0.05 元台幣 |
| 翻譯 500 字文章 | 800 | 800 | $0.010 ≈ 0.3 元台幣 |
| 摘要 10 頁 PDF | 8,000 | 500 | $0.025 ≈ 0.8 元台幣 |
| 寫 2,000 字部落格 | 300 | 3,000 | $0.031 ≈ 1 元台幣 |
| 分析 100 頁合約 | 80,000 | 2,000 | $0.22 ≈ 7 元台幣 |
| 整本書(30 萬字)摘要 | 500,000 | 5,000 | $1.30 ≈ 40 元台幣 |
$1 美元能買到什麼?
- ~600 次 簡單問答
- ~100 份 PDF 摘要
- ~32 篇 2,000 字文章
- ~4 份 長合約分析
- 1 次 整本書摘要
個人使用幾乎用不完 $5,但開發者和企業會碰到真實帳單——一個一天處理 10 萬封信的 AI 客服,月費可能到 $3,000–10,000。
想先估算你的應用月費?用我們的 API 成本試算器。
🔑 為什麼 AI 會「忘記」?三個常見 token 問題
1. AI 聊太久開始忘記前面的事
原因:對話 token 累積超過 context window,最早的內容被擠出記憶。
解法:開新對話,把關鍵背景資訊重新貼上。不要試圖和快溢位的 context window 硬凹——它只會越忘越多。
2. AI 回答到一半突然停住
原因:碰到「輸出上限」——多數模型單次輸出上限 4K–8K token(約 3,000–6,000 中文字)。
解法:打「請繼續」,或 prompt 中明確指定「分段輸出、每段不超過 X 字」。
3. Token 用量突然暴增
三個常見原因:
- 對話歷史越堆越長 → 用 Summary Window(每 10 輪讓 AI 自我摘要)
- System prompt 過長 → 啟用 Prompt Caching(重複 prompt 可享 50–90% 折扣)
- 重複問題 → 用 Embedding 快取,常見問題從向量資料庫直接取答案
🎯 省 token 的實戰技巧
基礎技巧(給 ChatGPT / Claude 一般使用者)
- 問題精準 — 少寫廢話、直接切入重點
- 指定長度 — 「用 100 字回答」比放生省一半 token
- 開新對話 — 不同任務別混在同一個對話
- 善用摘要 — 長文先摘要再討論細節
進階技巧(給 API 開發者)
- Prompt Caching:重複的 system prompt 享 50–90% 折扣(Claude 高達 90%)
- Batch API:非即時任務用批次跑,價格打 5 折
- 輸入壓縮:少用贅語、多用 JSON / 結構化格式
- 模型分層:高頻簡單任務用 Haiku / Flash / DeepSeek,複雜任務才升級 Opus / GPT-5
📎 深入 中日文使用者特別注意:CJK 語言在現代 LLM 上比英文多吃 10–60% token(和常見流傳的說法相反)。完整解析與各廠牌 tokenizer 對照請看 token-efficiency 專題。
🏗️ Token 與 AI 應用開發
輸入 vs 輸出的成本差異
輸出 token 比輸入貴 3–5 倍——這對應用設計有直接影響:
- ❌ 讓 AI「自由發揮」寫長答 = 花在輸出上的錢最多
- ✅ 在 prompt 中明確指定長度限制、用結構化格式輸出 = 省錢
Prompt Caching:給開發者的最大省錢術
當應用每次呼叫都送一樣的 system prompt(客服角色設定、知識庫摘要),這些不變的 token 會被重複計費。2026 年主流 API 都支援 Prompt Caching:
| 平台 | Cache 折扣 |
|---|---|
| Anthropic Claude | input 降至 10%(90% off) |
| OpenAI GPT | input 降至 50%(50% off) |
| Google Gemini | input 降至 25%(75% off) |
對知識庫型應用,system prompt 往往佔總輸入 80% 以上——啟用 caching 後 API 費用直接砍半以上。詳見 AI API 整合。
🌊 Token 經濟:2026 年的新詞彙地圖
以下是黃仁勳 GTC 2026 後流行起來的 token 相關概念——和這些詞打交道的人越來越多:
| 概念 | 說明 |
|---|---|
| AI Factory(AI 工廠) | 把電力 + 資料轉換成 token 的生產設施,取代傳統「資料中心」 |
| Tokens per Watt(每瓦 token 產量) | 衡量 AI 基礎建設效率的新指標 |
| Reasoning Tokens(推理 token) | 思考模型(o1、Claude thinking、DeepSeek R1)內部推理用 token,消耗比一般回答高 10–100 倍 |
| Inference Inflection(推理拐點) | 2026 年 AI 運算重心從「訓練」轉向「推理」的結構性變化 |
| Token Budget(token 預算) | 個別工程師 / 專案可支配的 token 額度,成為企業管理成本的新單位 |
| Tokenomics(token 經濟學) | 研究 token 生產成本、訂價策略、市場供需的新學科 |
❓ FAQ
為什麼黃仁勳要把 token 講這麼多次?
因為 NVIDIA 的商業敘事從「賣 GPU」升級為「賣 token 生產能力」。GPU 是工具、token 是產品——把終端客戶關心的東西(token)和自家硬體綁在一起,比純講 FLOPS / 頻寬更有說服力。
這個策略也解釋了為什麼他會提出「Revenue = Tokens/Watt × Gigawatts」這種公式——把 NVIDIA 的價值定位為 AI 經濟的基礎產能,和 OPEC 在石油經濟的角色類似。
為什麼 1 個中文字不等於 1 個 token?
Token 是模型的「詞彙單位」,不是「字元單位」。英文的 tokenizer 會合併常見字(“hello” = 1 token),中文的 tokenizer 多半把每個漢字當獨立 token(甚至罕見字會被切成 2 個 byte 片段)。
結果是中文字元數少,但 token 數反而多——同樣一句話用中文寫,token 數通常比英文多 30–60%。完整實測見 token-efficiency。
我不是開發者,需要在意 token 嗎?
日常用免費版 ChatGPT / Claude / Gemini 不需要。但三個情況你會遇到 token 限制:
- 聊太久 AI 開始忘記前面(超過 context window)
- AI 回答到一半停住(達到輸出上限)
- 上傳超長 PDF 被拒絕
遇到這些,開新對話 + 重點摘要就能解。
Token 用量怎麼查?
- ChatGPT / Claude 網頁版:沒有公開 token 數,只能透過「訊息次數 / 小時」限制間接感受
- API 呼叫:每次 response 的 JSON 會包含
usage.input_tokens/usage.output_tokens——這是 100% 準確的數字 - 離線估算:用本頁的 Token 視覺化工具,或 Python 的
tiktoken套件
上下文窗口越大越好嗎?
不一定,三個理由:
- 中間遺忘:當 context 塞到 60–80% 滿時,AI 對中間段落的理解會明顯下降
- 延遲爆增:1M token 輸入首 token 延遲可達 15–30 秒
- 階梯漲價:部分模型對超長 context 會收更高費率(Gemini 3 Pro 過 128K 後價格翻倍)
Token 和 Embedding 有什麼不同?
- Token:輸入給模型的離散單位(「這段文字由 150 個 token 組成」)
- Embedding:token 被轉換後的向量表示(一串浮點數,通常 1536 或 3072 維)
比喻:Token 是「門票」,Embedding 是「你在房間裡的座標」。RAG 系統用 Embedding 做相似度搜尋,但最終還是把文字以 token 形式送進 LLM。深入見 Embedding 是什麼。
黃仁勳說工程師薪水附 token 額度,這是什麼意思?
GTC 2026 黃仁勳講了一段引發熱議的話:「在 Silicon Valley,token 已經變成招募工具。工程師面試會問『我這份工作配多少 token?』」
邏輯:工程師使用 Claude / GPT / Cursor 的頻率決定生產力。公司給工程師充足的 API 額度,相當於給一個「10 倍放大鏡」——這筆投入比加薪划算。預期 2026–2027 年,API token 額度會成為科技公司 package 的標準項目,就像當年的 MacBook 配發。
Reasoning token 和一般 token 有什麼不同?
- 一般 token:直接產生給使用者看的回答
- Reasoning token / Thinking token:模型內部推理用的 token,通常不顯示,但會計費
像 OpenAI o1、Claude Extended Thinking、DeepSeek R1 這類思考模型,會在回答前先「想」很多步——這段思考過程消耗的 token 可能是最終回答的 10–100 倍。這也是為什麼黃仁勳強調「推理時代」會把運算需求推升到新高度。
黃仁勳說 token 是 AI 新貨幣,這對 NVIDIA 投資人意味什麼?
這是一個敘事升級——把 NVIDIA 從「賣 GPU 的半導體週期股」定位為「賣 token 生產力的 AI 基礎建設公司」。這個定位如果被市場接受,本益比可接受的區間從 20 倍拉到 40–50 倍,對應的是幾千億美元的市值差距。
但要注意:敘事需要業績驗證。未來 2–3 年要看的不是黃仁勳演講,而是:
- Microsoft / Google / Meta / Amazon 四家資本支出是否持續成長
- NVIDIA 的毛利率能否維持 70%+(反映議價能力)
- 推理市場是否真的放大 10–100 倍 token 需求
投資決策自己判斷,這篇只解釋商業邏輯。
token 需求真的會有 1 兆美元嗎?會不會像 dot-com 泡沫?
合理但有折扣的樂觀。拆開看:
- ✅ 推理時代確實在發生:o1、R1、Claude thinking 等模型上線後,單次任務的 token 消耗確實放大 10–100 倍——這是可驗證的技術事實
- ⚠️ 1 兆美元是 NVIDIA 自家預測:黃仁勳有強烈動機把數字講高。類比:石油公司 CEO 說全球能源需求翻倍時也不是騙人,但他絕不會講保守版本
- 🔍 泡沫 vs 真實需求的差別:dot-com 泡沫時期的問題不是「網路不普及」,是「太多錢投入到還沒 monetize 的商業模式」。目前 AI 有類似徵兆(OpenAI / Anthropic 還在虧錢),但資本支出的終端用戶(Microsoft、Google 等)是會賺錢的公司,這點和 dot-com 不太一樣
最可能的情境:方向對、節奏偏樂觀——需求會成長但不會照黃仁勳的時間表。
除了 NVIDIA,還有哪些產業會受惠 token 經濟?
token 經濟的產業鏈傳導(商業邏輯整理,不是推薦):
- HBM 記憶體:token 運算吃記憶體頻寬,SK Hynix、Samsung、Micron 都在擴產
- 先進封裝 / 散熱:Blackwell 熱密度極高,CoWoS、液冷、先進封裝產能吃緊
- 電力 / 能源:黃仁勳點名 token 工廠會缺電,相關標的包含核能、小型模組反應爐(SMR)
- 雲端超大規模業者:Microsoft、Google、Amazon、Meta——花最多錢買 GPU,但也掌握終端需求
- 台股連動:台積電(CoWoS)、聯電、鴻海、廣達、緯穎、智邦、奇鋐、雙鴻等都在這條產業鏈上
風險:產業鏈估值普遍已反映大量預期。投資決策請諮詢合格理財顧問。
📚 Token 經濟完整學習路徑
本站整理了從「token 是什麼」到「如何省錢」的完整 token 經濟內容:
基礎理解
- 🧭 本篇 — Token 是什麼?黃仁勳的 AI 新貨幣
- 🔍 中文比英文省 token?實測破除 CJK tokenizer 迷思 — 含互動工具
- 🧠 Context Management 深入 — 長 context 管理
實戰省錢
- 💰 API 成本試算器 — 7 家模型月費對比
- 🔧 AI API 整合 — prompt caching、batch API
- 🎯 Prompt Engineering — 寫好 prompt 省 token
產業脈絡
- 🚀 Claude Opus 4.7 正式發布 — 最新 tokenizer 變動
- 🏭 NVIDIA GTC 2026:黃仁勳三大押注 — Token 工廠敘事源頭
- 📊 模型雪崩:2026 模型速度 — 為什麼 token 定價一直變