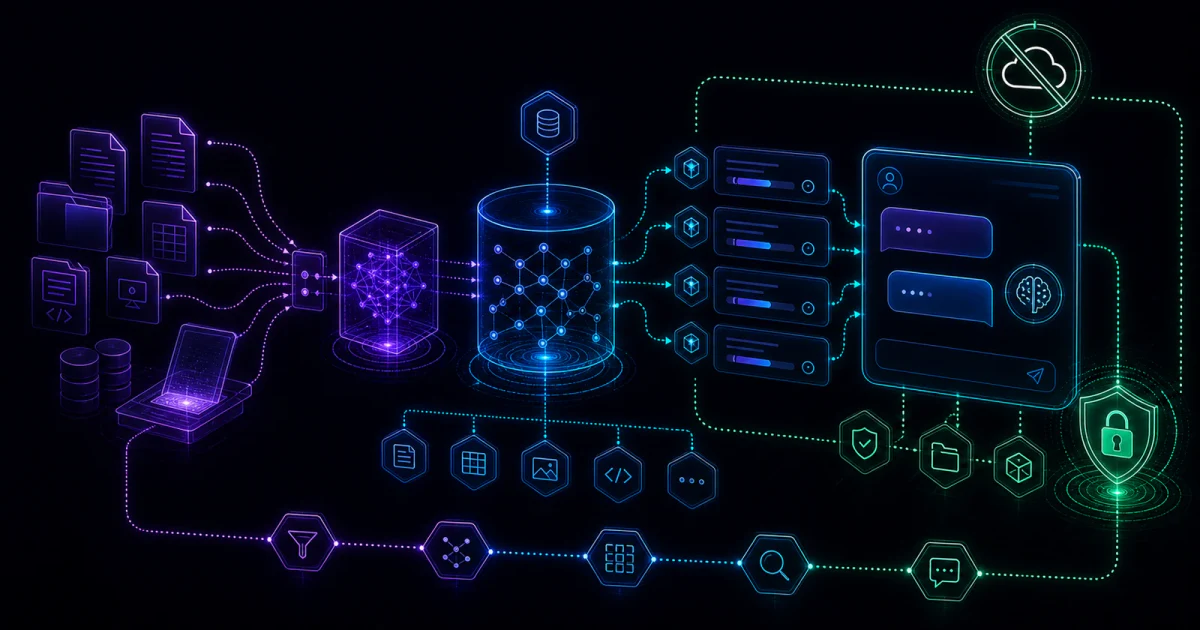
如果你想把公司 SOP、PDF、合約範本或個人筆記接進本機大語言模型(local LLM),AnythingLLM 可以是最快上手的文件問答工作區。不要一開始就追求全公司知識庫、Agent 自動化和大模型部署;先做一個可驗證的小型工作區,確認它真的找得到來源、答得出缺漏,才值得擴大。
個人使用先裝 AnythingLLM Desktop,建立一個工作區(workspace),只放 10 到 30 份主題一致的文件,接一個你已經跑穩的模型,再用本文的驗證問題測「引用是否正確」。如果要多人帳號、權限、備份和伺服器部署,再改走 Docker;如果不想維運伺服器,才評估官方 Cloud。
先選路線:桌面版(Desktop)、Docker 還是官方 Cloud?
AnythingLLM 官方把 Desktop 和 Docker 視為兩條主要使用方式;Cloud 是由官方代管的私有實例。選錯路線會讓你在不該維運的地方維運,或在需要權限治理時只剩單人桌面應用程式(App)。
| 路線 | 適合情境 | 你要先確認什麼 |
|---|---|---|
| Desktop | 個人、SOHO、研究資料庫、小量文件 PoC | 文件是否留在本機、模型能不能跑、引用是否可靠。 |
| Docker 自架 | 小團隊、內部知識庫、需要多人帳號與權限 | 伺服器、資料卷、備份、登入模式、模型 API 和網路邊界。 |
| Cloud | 想省維運、需要官方代管私有實例 | 月費、LLM API key、資料政策、支援 SLA 和供應商風險。 |
截至 2026-06-18 查核,AnythingLLM 官網 Cloud 頁面列出 Basic 為每月 50 美元、Pro 為每月 99 美元;同頁也寫明可用 Docker 免費執行。這些費用不等於模型成本:你若接 OpenAI、Anthropic、Gemini、OpenRouter 或租 GPU,自然還會有模型 API、算力和維運費用。
AnythingLLM 是什麼?它在本機 AI 工作流裡扮演哪一層
AnythingLLM 可以把文件、對話、工作區、模型供應商、嵌入模型(embedding model)、向量資料庫(vector database)和代理工具(Agent)功能放在同一個應用裡。對想做文件問答的人來說,它的價值在於把 RAG 工作流包成比較可操作的介面;模型品質仍要回到你選的本機或雲端模型。
| 工具 / 元件 | 在工作流裡做什麼 | 常見誤解 |
|---|---|---|
| AnythingLLM | 管理工作區、文件、檢索、聊天與部分 Agent 功能 | 把它當成模型本身。 |
| Ollama | 在本機跑對話模型或嵌入模型,常見預設端點是 http://127.0.0.1:11434 | 只要裝 Ollama 就完成 RAG。 |
| LM Studio | 桌面模型下載、聊天與本機 API 測試 | 適合每個多人知識庫場景。 |
| Open WebUI | 自架 AI 入口、多模型聊天、Ollama 介面與 RAG | 和 AnythingLLM 目標完全重疊。 |
| NotebookLM | 快速研究一組來源、摘要與筆記 | 適合取代自架權限與模型選擇。 |
如果你的第一個問題是「我能不能把文件丟進去問」,AnythingLLM 比單純 Ollama 更接近需求;如果你的第一個問題是「我想讓公司同事有一個像 ChatGPT 的共用入口」,Open WebUI 也應該一起比較。
本機 RAG 最短路徑:先做一個可測的小工作區
1. 先畫資料邊界
不要把整個硬碟、全部 Google Drive 或所有公司資料一次倒進去。第一輪只選一個任務:
- 客服 FAQ 和退款流程。
- 某產品線的說明文件。
- 20 份合約範本。
- 一門課的講義和閱讀清單。
- 一組研究 PDF 和自己的筆記。
資料邊界越清楚,檢索增強生成(RAG)越容易被驗證。主題混雜、版本重複、掃描 PDF 沒做文字辨識(OCR)、檔名沒有語意,都會讓模型看起來「懂」,但其實抓錯段落。
2. 選桌面版或 Docker,不要一開始就混 Cloud
個人測試先用 Desktop,因為安裝和資料位置最容易理解。官方 Desktop 文件寫明,Desktop 是單人桌面應用程式(single-player app),適合本機 LLM、RAG 和 Agent,並強調不需要多人支援、資料要留在裝置上的使用情境。
要讓多個人登入、管理角色、分享工作區或發布網站聊天小工具,再走 Docker。官方 Docker 快速開始(quickstart)的重點是持久化資料卷;如果沒有掛載儲存資料夾(storage),容器重啟後資料可能遺失。這比模型選哪一個更早要決定。
3. 把模型、嵌入模型和向量資料庫分開選
RAG 至少有三層模型與資料選擇:
| 層 | 你在 AnythingLLM 裡要決定什麼 | 為什麼重要 |
|---|---|---|
| 大型語言模型(LLM) | 系統模型、工作區模型或 Agent 專用模型 | 決定回答、摘要、推理和工具使用品質。 |
| 嵌入模型 | 把文件片段轉成向量 | 決定問題能不能找到相關段落;換模型通常要重嵌入文件。 |
| 向量資料庫 | 儲存文件向量 | 官方文件提醒,向量資料庫是系統層設定,遷移時不會自動搬移已嵌入資料。 |
官方文件也提醒,AnythingLLM 的內建嵌入模型會在第一次嵌入時下載約 25MB,主要訓練在英文資料;如果你的內容是繁中合約、公司 SOP 或雙語文件,請把中文檢索測試放進第一輪,而不是等上線後才發現找不到來源。
4. 先用「附加文件」和「嵌入文件」分清楚測試方式
AnythingLLM 1.8.5 之後的文件使用方式,官方分成「附加文件(attaching documents)」和「嵌入文件(embedding documents)」。簡單說:短文件可以直接附加到對話上下文;要讓文件跨對話串(thread)、跨對話長期可用,就要把文件嵌入工作區,走 RAG。
這裡最容易踩坑:RAG 不會把整套文件塞進模型腦袋。官方舊版說明用很白話的方式提醒,傳統 RAG 會根據問題去向量資料庫抓回少量相關片段;如果問題太籠統、文件切段不佳或嵌入模型不適合,模型可能根本沒有拿到正確材料。
5. 用驗證問題決定是否擴大
建立工作區後先問這些問題,不要急著問「幫我寫一份完整報告」。
請列出目前知識庫中有哪些文件,依主題分類,並指出你看不到哪些資訊。請找出所有提到「退款」的段落,列出文件名稱、段落重點,以及你不確定的地方。根據知識庫回答:客戶要求取消訂單時,客服應先確認哪些條件?
請把答案分成:直接答案、引用依據、文件沒有說明的地方、建議下一步。如果知識庫沒有答案,請明確回答「文件沒有提供足夠資訊」,不要用常識補完。如果這些問題抓不到正確來源,先整理文件、調整嵌入模型或重做切段;不要用更複雜的提示詞掩蓋檢索問題。
本機、自架、雲端的成本和硬體怎麼看
AnythingLLM 不是模型,所以沒有「幾 B 參數」這種規格。你要評估的是:應用本身跑在哪裡、模型跑在哪裡、嵌入模型跑在哪裡,以及資料要不要離開你的設備。
| 成本問題 | Desktop / 本機 | Docker 自架 | Cloud / 雲端模型 |
|---|---|---|---|
| 應用程式本身(App) | 開源版可免費使用;資料主要在本機儲存。 | Docker 可免費跑,但要伺服器、備份和維運。 | 官方代管有月費;仍要看模型 API 成本。 |
| 模型推論 | 本機模型吃 CPU、RAM、顯示記憶體(VRAM)和 SSD。 | 可接另一台有 GPU 的模型機,也可接雲端 API。 | 品質穩定但依供應商和用量計費。 |
| 文件嵌入 | 內建或本機嵌入模型成本低,但中文效果要測。 | 大量文件會吃 CPU、記憶體與儲存。 | Cloud 文件提醒內建嵌入模型在大文件情境可能受 CPU 限制。 |
| 團隊治理 | 個人最省事,但多人使用弱。 | 可以做多人和權限,但要管理登入、資料卷、更新。 | 省維運,但要接受資料在代管環境裡。 |
官方 Desktop 系統需求文件給的基準是:若要本機模型有基本體驗,建議 16GB RAM 和 8-core CPU;Windows 若要本機 LLM 更快,8–12GB 以上 VRAM 會更理想。Docker 版的應用本身門檻較低,官方文件列出 2GB RAM、2-core CPU、5GB 儲存空間(storage)作為基本值;真正的瓶頸通常仍是模型和文件嵌入。
實務判斷可以這樣做:
- 只是個人文件問答:Desktop + 小型工作區。
- 已經有 Ollama 或 LM Studio:先把本機模型跑穩,再接 AnythingLLM。
- 團隊要共用文件庫:Docker,並設計登入、角色、備份、刪除流程。
- 要高品質中文摘要、長文件或穩定推理:保留雲端 LLM API 作為候選,不要只看「本機免 token」就下決定。
- 要大量使用者或高峰流量:把自架 GPU、雲端 API、官方 Cloud 和維運人力一起算。
權限與資料風險:私有不等於不用治理
AnythingLLM Desktop 的官方隱私政策寫得很直接:訊息、聊天歷史和文件預設不會從你的系統傳出,資料儲存在本機;它也提到可在 App 設定中關閉使用資料回報(telemetry)。這對個人和小型 PoC 很有價值。
但正式用在公司內部時,還要補上這些控制:
- 文件分級:哪些可進 AnythingLLM,哪些只能人工查閱。
- 使用者權限:Docker 版才有更完整的單人 / 多人模式與角色概念;進入多人模式(multi-user mode)後,官方文件提醒不能再回到單人模式(single-user mode)。
- 模型供應商政策:接雲端 LLM 時,資料處理規則看供應商,不看 AnythingLLM 介面。
- 資料卷與備份:Docker 部署時,資料卷(storage volume)是知識庫生命線。
- 刪除與重嵌入流程:文件被移除、嵌入模型更換或向量資料庫改動時,要有重建索引的流程。
- 對外網路:不要把 Docker 服務、Ollama API 或 LM Studio 伺服器(server)直接暴露到公開網路。
AnythingLLM 和 Open WebUI、NotebookLM 怎麼選
| 你真正想完成的事 | 優先工具 | 理由 |
|---|---|---|
| 個人或小團隊文件問答、私有知識庫 | AnythingLLM | 文件、工作區、RAG 和模型供應商(provider)放在同一個工作區。 |
| 把 Ollama 變成瀏覽器介面,讓多人聊天 | Open WebUI | 介面、模型入口、多使用者和 Ollama 搭配更直覺。 |
| 快速研究少量來源、做筆記和摘要 | NotebookLM | 少維運、來源型研究更快。 |
| 桌面下載模型、開本機 API、偶爾丟文件問答 | LM Studio | 單人桌面模型工作台更輕。 |
| 企業知識庫聊天機器人(chatbot)、API 嵌入產品 | CustomGPT.ai 或自建 RAG | 產品整合、API、權限、客服場景要另外比較。 |
如果你只需要單次整理 PDF,NotebookLM 或 ChatGPT 通常比較快。AnythingLLM 的優勢在於長期維護:文件會更新、模型會更換、團隊會增加、權限會變複雜,這時工作區和 RAG 設定才有價值。
常見錯誤與修正
| 錯誤 | 會發生什麼 | 修正方式 |
|---|---|---|
| 一次匯入所有資料 | 檢索混亂、答案看似流暢但來源錯 | 先做單一主題、小文件集,再逐步擴大。 |
| 用聊天模型當嵌入模型 | 文件無法正確嵌入或檢索品質差 | 在 Ollama / LM Studio 裡確認選的是嵌入模型(embedding model)。 |
| 換嵌入模型(embedder)後不重嵌入 | 舊文件向量和新模型不一致 | 刪除並重嵌入相關文件,記錄變更時間。 |
| 只看答案,不看引用 | 幻覺不容易被發現 | 要求列出文件名稱、段落重點和不確定處。 |
| 把本機等於免費 | 硬體、SSD、電費、維運、人工校對仍有成本 | 把 App、模型、API、GPU 和人力分開算。 |
| Docker 沒掛資料卷 | 容器重建後資料可能遺失 | 依官方快速開始(quickstart)掛載儲存資料夾,並建立備份。 |
| 沒設權限就讓團隊使用 | 所有人可能看到不該看的文件 | 先決定單人模式 / 多人模式、角色和文件分區。 |
一週測試計畫
第 1 天:安裝與資料邊界
選 Desktop 或 Docker,只匯入一組小型資料。記錄文件數量、格式、版本和哪些資料刻意不放進去。
第 2 天:模型與嵌入模型
先用一個你已經理解成本和資料政策的 LLM。若接本機 Ollama,先確定 Ollama 教學裡的模型、GPU 和 API 都能正常運作;若接雲端模型,先確認費用和資料政策。
第 3 天:建立工作區和驗證題
建立一個工作區,放入 10 到 30 份文件,用前面的四組問題測引用、缺漏和錯誤處理。
第 4 天:整理文件格式
處理掃描 PDF、表格、重複頁首、舊版文件和命名混亂。RAG 的品質常常在這一天改善最多。
第 5 天:權限和備份
如果要讓別人用,先設計誰能看哪些文件、誰能上傳、誰能刪除、備份在哪裡、如何回復。
第 6 天:比較替代工具
若使用者主要抱怨「沒有好用介面」,比較 Open WebUI;若抱怨「本機模型不好跑」,回到 LM Studio或 Ollama;若只是研究一批文件,試 NotebookLM。
第 7 天:決定擴大、重做或停止
只有在引用、缺漏標示、權限和成本都可接受時,才擴大文件量。若第一週就需要大量人工校對,先縮小資料範圍或改用更高品質模型,不要急著導入全公司。
FAQ
AnythingLLM 是免費的嗎?
AnythingLLM Desktop 和 Docker 自架路線可使用開源版,官網也寫明 AnythingLLM 是開源、可免費使用,並採 MIT 授權(MIT license)。若使用官方 Cloud,2026-06-18 查核頁面顯示 Basic $50/月、Pro $99/月;接雲端 LLM 或租 GPU 時,模型/API/算力成本要另外計算。
AnythingLLM 一定要搭配 Ollama 嗎?
不一定。AnythingLLM 可接多種本機與雲端 LLM 模型供應商(provider);Ollama 只是常見本機模型路線。如果你已經用 OpenAI、Anthropic、Gemini、Mistral、OpenRouter 或 LM Studio,也可以依官方模型供應商設定接入。重點是先弄清楚模型成本、資料政策和品質。
AnythingLLM 適合中文文件問答嗎?
可以測,但不要只看回答是否通順。中文文件要特別驗證檔名、章節、OCR、表格、嵌入模型和引用段落。官方內建嵌入模型主要訓練在英文資料;如果繁中檢索不穩,優先測支援多語的嵌入模型,並重新嵌入文件。
Desktop 和 Docker 版怎麼選?
一個人先用 Desktop,速度最快、資料邊界也最清楚。要多人登入、角色權限、伺服器部署、網站聊天小工具或集中備份,再用 Docker。Docker 路線要先處理資料卷、網路、登入模式、備份和更新策略。
RAG 為什麼有時候沒有用到我的文件?
常見原因是問題太籠統、文件切段不佳、嵌入模型不適合語言、向量資料庫裡沒有正確片段,或模型上下文沒有拿到相關內容。先用「列出來源文件」「找出某關鍵段落」「文件沒有說明時明確標示」這類驗證題排查,再調整文件和嵌入設定。
參考資料
- AnythingLLM 官方網站
- AnythingLLM Cloud Pricing
- Mintplex-Labs / anything-llm GitHub README
- AnythingLLM Desktop Installation Overview
- AnythingLLM Desktop Privacy Policy
- AnythingLLM Docker Quickstart
- Using Documents in AnythingLLM
- AnythingLLM Embedder Configuration
- AnythingLLM Vector Databases
- AnythingLLM Security and Access