
✨ 什麼是生成式 AI?
🎯 一句話理解 生成式 AI = 能「創造」新內容的 AI。不只是分析數據,而是能寫文章、畫圖、做音樂、拍影片——從無到有產出全新的內容。
和傳統 AI 的差別
| 傳統 AI | 生成式 AI | |
|---|---|---|
| 做什麼 | 分析、分類、預測 | 創造、生成、轉換 |
| 輸出 | 標籤、數字、機率 | 文字、圖片、音樂、影片 |
| 範例 | 垃圾郵件過濾 | ChatGPT 寫文章 |
| 核心技術 | 決策樹、SVM | Transformer、Diffusion |
📝 文字生成(LLM)
大型語言模型(LLM)是生成式 AI 的代表。ChatGPT、Claude、Gemini 都屬於這類。
核心技術
LLM 基於 Transformer 架構,核心能力是「預測下一個詞」。但透過海量數據的訓練,這種簡單的能力衍生出了驚人的智慧——寫作、推理、翻譯、程式碼⋯⋯
主要玩家
- GPT 系列(OpenAI)— 最知名,生態系最完整
- Claude(Anthropic)— 寫作最自然,程式碼最好
- Gemini(Google)— 多模態最強,搜尋整合
更多比較請看 GPT vs Claude vs Gemini
🖼️ 圖像生成
AI 圖像生成在 2022-2024 年間經歷了爆炸性成長,從粗糙的塗鴉到照片級的真實感。
三大技術路線
- Stable Diffusion — 開源、可本地運行、高度可控,社群生態豐富
- DALL-E 3 — OpenAI 出品,與 ChatGPT 深度整合,最容易使用
- Midjourney — 美學品質最高,特別擅長藝術風格
💡 擴散模型原理 擴散模型的核心很簡單:先教 AI 如何把清晰圖片「加噪」變模糊,然後反過來讓 AI 學會從噪音中「還原」出清晰圖片。生成新圖片時,AI 從純雜訊開始,一步步去噪,就「想像」出了一張新圖。
詳細教學:AI 繪圖指南
🎬 影片生成
2024 年 OpenAI 的 Sora 震撼了全世界,到 2026 年 Sora 2 已支援 25 秒高品質影片及同步音訊,影片生成 AI 正式進入實用化階段。
主要玩家
| 工具 | 開發商 | 特色 |
|---|---|---|
| Sora | OpenAI | 物理模擬極佳,畫面連貫性最高 |
| Runway Gen-4 | Runway | 專業影像工作者首選,角色一致性和運鏡控制最強 |
| Kling | 快手 | 開放免費使用,支援長影片 |
| Pika | Pika Labs | 輕量易用,適合社群媒體短片 |
⚠️ 目前的限制 影片生成 AI 仍有明顯限制:物理定律偶爾失效、人物手指數量不穩定、長影片一致性差。目前更適合短片和特效輔助。
🎵 音樂與語音
AI 不只能生成文字和圖片,還能譜曲和說話。
音樂生成
- Suno — 輸入「一首關於台北雨天的爵士歌曲」,就能生成完整歌曲(含人聲!)
- Udio — 音質更專業,適合音樂人使用
語音技術
此為聯盟連結 敬請支持本站
- ElevenLabs — 極度逼真的語音合成和語音克隆
- 語音克隆 — 只需 3-10 秒的語音樣本,就能複製一個人的聲音
- 即時翻譯配音 — AI 用你自己的聲音說其他語言
第一次測試語音工具時,不要急著克隆正式聲音。先丟一段 20-30 秒短稿,聽它怎麼處理停頓、人名、數字和英文品牌名,再決定要不要放進 YouTube、Podcast 或課程內容。
🌐 多模態 AI
多模態 AI 是 2025-2026 的最大趨勢——讓 AI 像人一樣同時「看」、「聽」、「讀」、「說」。
💡 多模態能做什麼?
- 🖼️ 看圖理解 — 上傳菜單照片,AI 翻譯並推薦料理
- 🎙️ 語音對話 — 像打電話一樣和 AI 聊天,它能聽到你的語氣
- 📹 影片分析 — AI 觀看教學影片並自動寫出筆記摘要
- 🔄 跨模態創作 — 用文字描述生成圖片,再從圖片生成影片
詳細教學:多模態 AI
⚖️ 創作倫理
AI 創作工具強大,但也帶來了深刻的倫理挑戰。
核心議題
| 議題 | 現況 | 建議 |
|---|---|---|
| 版權歸屬 | 法律仍在討論中 | 保存生成紀錄 |
| 訓練數據 | 藝術家抗議中 | 關注平台政策 |
| 標示義務 | 部分平台要求 | 主動標示 AI 生成 |
| 深偽技術 | 法規逐步完善 | 不製作深偽內容 |
⚠️ 負責任的使用 在使用 AI 創作工具時,請:明確標示 AI 生成的內容、尊重原創作者的權利、不製作或傳播深偽內容、注意生成內容可能帶有的偏見。
詳細討論:AI 倫理法規
🧠 生成式 AI 的技術演進:從 GAN 到 Transformer
理解生成式 AI 的發展脈絡,能幫你判斷哪些技術已經成熟、哪些還在實驗階段。
三代核心技術
| 世代 | 技術 | 代表作 | 特色 |
|---|---|---|---|
| 第一代(2014-2017) | GAN(生成對抗網路) | DeepFake、StyleGAN | 兩個神經網路互相競爭,一個造假一個抓假,越打越強 |
| 第二代(2017-2022) | Transformer + 自迴歸 | GPT-3、BERT | 注意力機制讓模型理解上下文關係,奠定 LLM 基礎 |
| 第三代(2022-now) | Diffusion + 大規模 Transformer | GPT-4o、DALL-E 3、Sora | 多模態融合,同一個模型能處理文字、圖片、影片、音訊 |
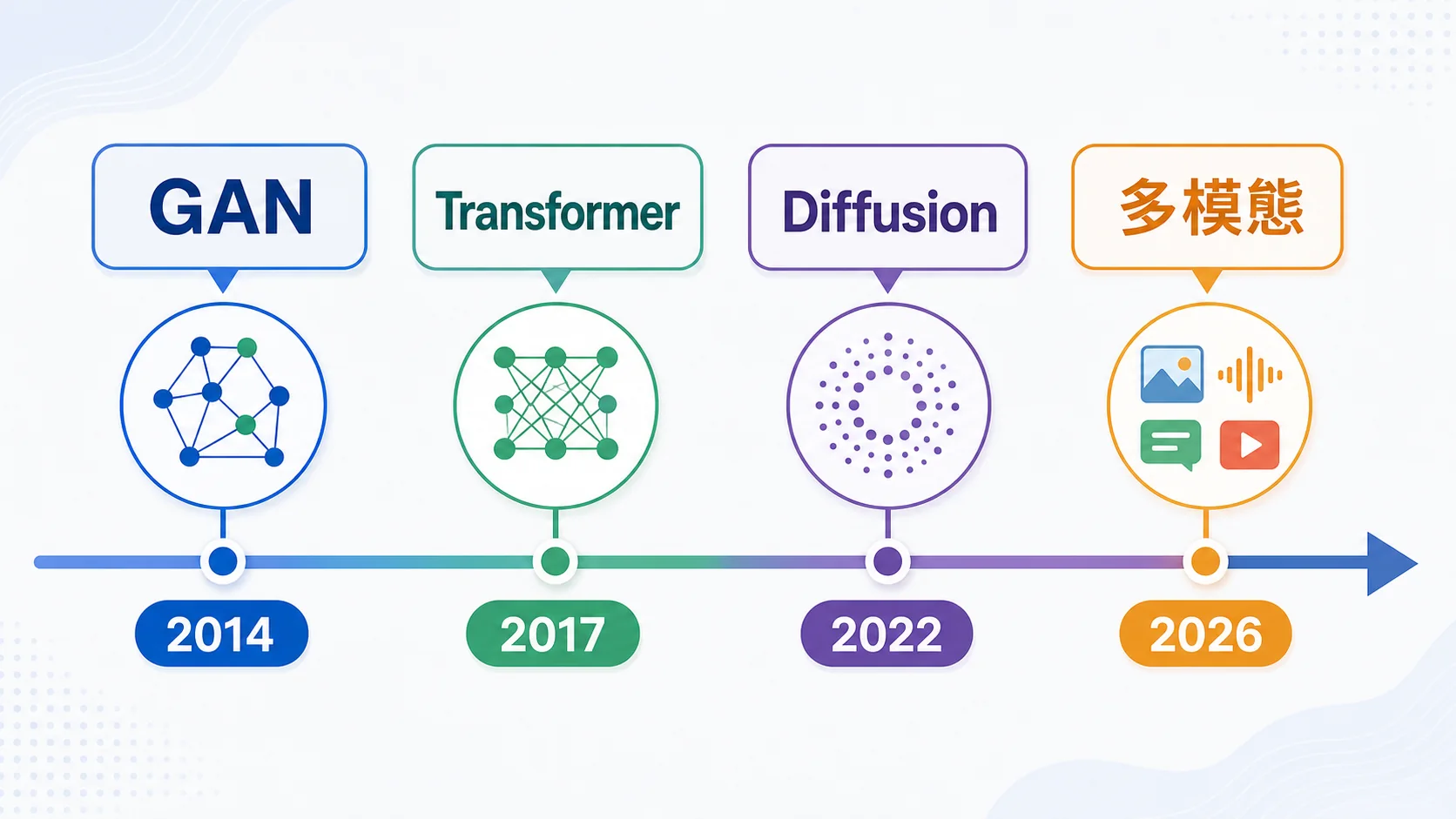
為什麼 Transformer 贏了?
GAN 的問題是訓練不穩定——兩個網路的對抗經常失衡,導致「模式崩塌」(只會生成少數幾種結果)。Transformer 的「自注意力機制(Self-Attention)」則能平行處理整段文字的上下文關係,不僅訓練更穩定,還能擴展到數千億參數的規模。這就是為什麼 2022 年之後,幾乎所有頂級 AI 模型都基於 Transformer 架構。
想深入理解 Transformer 的運作原理,可以參考 AI 是怎麼思考的?。
🔮 2026 年生成式 AI 的前沿趨勢
Agent(AI 代理人)
生成式 AI 的下一步不只是「回答問題」,而是「自主完成任務」。AI Agent 能拆解複雜目標、規劃步驟、呼叫工具、自我修正。例如:你說「幫我研究三家競品並做一份簡報」,Agent 會自動搜尋資料、整理分析、生成投影片,中間不需要你一步步指揮。
了解更多:AI 自動化架構師的崛起
小模型的反攻
不是所有場景都需要 GPT-4 等級的巨獸模型。2025-2026 年,小型語言模型(SLM) 如 Phi-3、Gemma 2 開始在手機和邊緣裝置上運行。優勢是成本低、延遲低、隱私好——你的資料完全不需要送上雲端。這對醫療、金融等高隱私需求的產業特別重要。
合成數據(Synthetic Data)
當真實世界的訓練數據不夠用時,AI 開始用 AI 生成的數據來訓練 AI。這聽起來像自我參照的悖論,但在特定場景(如自駕車模擬、罕見疾病影像)中,合成數據已經是不可或缺的訓練資源。
❓ FAQ
生成式 AI 和傳統 AI 有什麼不同?
傳統 AI 擅長「分析」——分類垃圾郵件、預測股價、推薦商品。生成式 AI 擅長「創造」——寫文章、畫圖、做音樂。兩者基於不同的技術架構,解決不同的問題。
生成式 AI 的作品有原創性嗎?
這是個哲學問題。AI 是從大量訓練數據中學習模式後「重新組合」成新作品。它不是簡單複製,但也不像人類有真正的「靈感」和「意圖」。法律上,大部分國家目前不承認 AI 作品的版權。
🎨 2026 生成式 AI 技術版圖
- 文字生成(LLM):Claude Opus 4.7、GPT-5.4、Gemini 3 Pro、DeepSeek V4——能力差距 < 20% 但單價差距 10–60x,詳見 API 成本試算器
- 影像生成:Midjourney v7、DALL-E 4、FLUX.1——突破:即時生成 + 精準文字渲染
- 影片生成:Sora 2、Google Veo 3、Runway Gen-4——60 秒以上一致性影片
- 程式碼:Claude Code、Cursor、GitHub Copilot——Opus 4.7 SWE-bench 達 87.6%
- 3D / 物理模擬:NVIDIA Cosmos、Google Genie、Meta V-JEPA
「生成式 AI」和「AI Agent」差在哪?
- 生成式 AI:輸入 → 產出內容(文字、圖、影片、程式)
- AI Agent:輸入 → AI 自主決策 + 執行多步驟動作
兩者不衝突——Agent 內部大量使用生成式 AI。詳見 AI Agent 生態。
生成式 AI 會取代創作者嗎?
不會完全取代,但會重構創作門檻:
- ✅ 底層技術門檻降低(以前要會畫圖才能做視覺,現在會描述就夠)
- ✅ 創意 / 品味仍不可取代
- ⚠️ 中階創作者壓力最大(會基本技巧但沒獨特品味)
- ✅ 頂級創作者反而強化(10x 產出)
策略:不要比誰 AI 用得熟,比誰用 AI 做出來的東西有獨特品味。
我可以用生成式 AI 做商業用途嗎?
看模型授權 + 場景:
- 文字(ChatGPT Plus / Claude Pro):付費版通常允許商用
- 圖片(Midjourney / DALL-E):付費版允許商用,免費版限制多
- Stable Diffusion:開源 + 商用友善
務必注意:商用前讀該服務的 Terms of Use——涉及版權爭議時你要自己承擔風險。