Multi-Agent 完整指南:你真的需要多代理嗎?
先講最重要的事:80% 場景單 agent 夠用。
繁中 + 英文 SERP 上的 multi-agent 文章清一色鼓吹「多 agent 是未來」——但 Mason 的觀察是:真實 production 多 agent 佔比 < 20%。
5 個信號告訴你不需要 multi-agent:
- 任務可以一個 prompt 講清楚 → 不需要
- 任務沒有「多個專業領域」參與 → 不需要
- 預算緊(multi-agent token 倍數 4-7 倍) → 不需要
- 沒 production 經驗 → 先從單 agent 開始
- 想學新東西 → 去學 Agent Design Patterns,先把單 agent 玩熟
3 個信號告訴你該用 multi-agent:
- 任務需要不同領域專家(研究 + 編譯 + 開發 = 3 個專業)
- 平行加速能帶來實質效益(I/O bound 任務)
- 預算寬鬆 + 對品質有極高要求
Mason 自己:每日 AI 新聞 triage agent 90% 任務用單 agent——只在「寫 insights 草稿 + 內容品質檢查」這種「多領域」任務用 multi-agent。
Multi-Agent 詞彙釐清
4 個詞常被混用,但定義不同**:
| 詞 | 定義 | 範例 |
|---|---|---|
| Subagent | 主 agent 派發給的子 agent(無狀態) | Claude Code 的 subagent |
| Multi-Agent | 多個獨立 agent 協作(可能有狀態) | CrewAI 的角色系統 |
| Agent Team | = Multi-Agent 的別稱(Claude Managed 用詞) | Anthropic Managed Agents |
| Swarm | 去中心化 agent 群 | OpenAI Swarm 框架 |
Mason 的觀察:Subagent 是「單 agent 內的子任務」,Multi-Agent 是「多個獨立 agent」——兩者差別在「獨立性 + 狀態」。
🏛️ 4 大編排架構
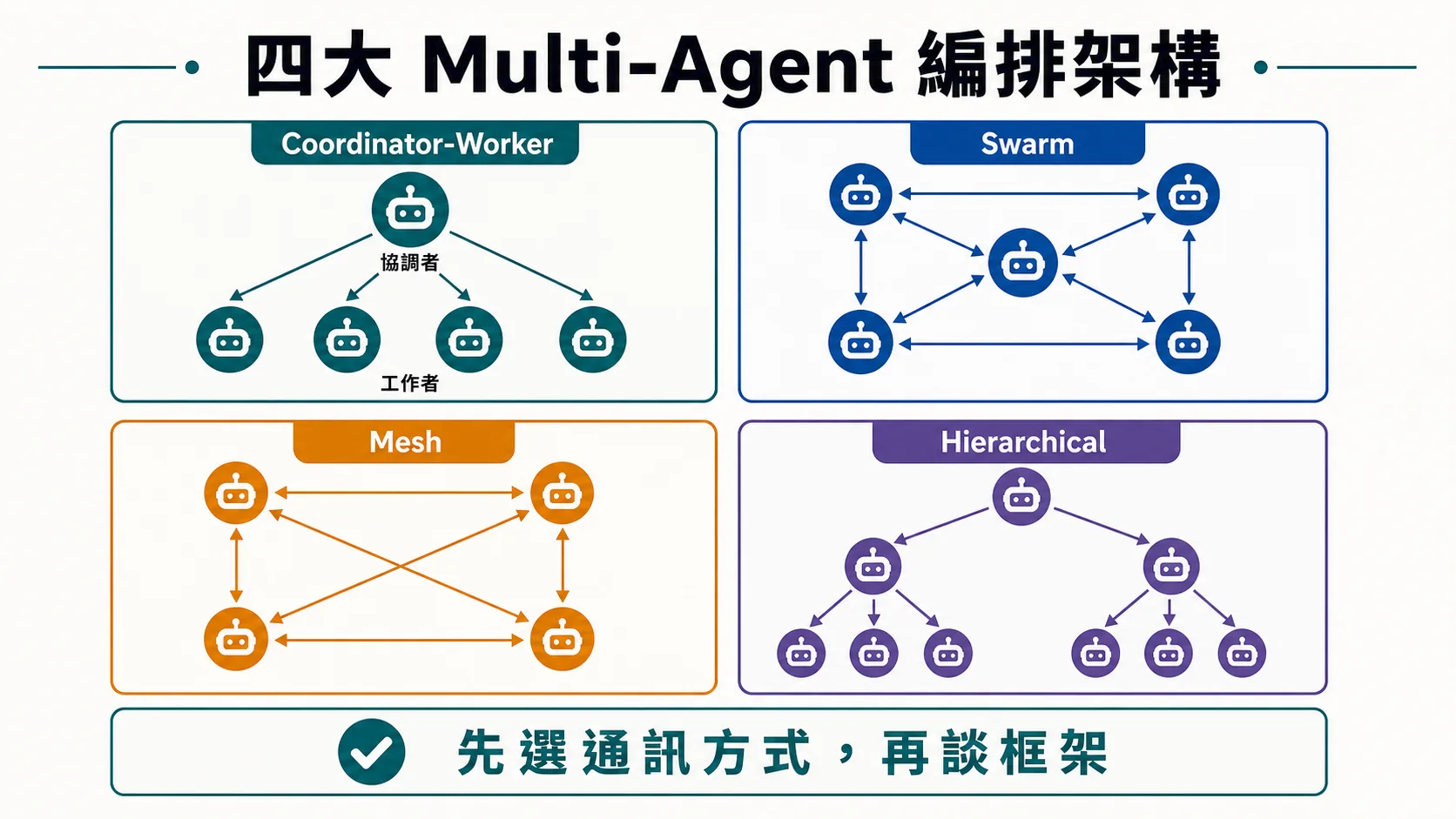
1. Coordinator-Worker(80% 場景)
架構:
[Coordinator]
↓ 派發任務
[Worker 1] [Worker 2] [Worker 3]
↓ 回傳結果
[Coordinator 合成]特性:
- 集中決策(Coordinator 規劃)
- 平行執行(Workers 同時跑)
- 單一 entry point(use cases 清晰)
何時用:
- 任務可清楚拆解成獨立子任務
- 需要最終合成 / 整合結果
真實案例:
- Anthropic Claude Managed Agents 預設架構
- Anthropic multi-agent research system(90% 平行)
- Claude Code 的 Plan Mode + Subagents
2. Swarm(去中心化)
架構:
[Agent A] ←→ [Agent B] ←→ [Agent C]
↑ ↑ ↑
└────────────┴───────────┘
(對等溝通)特性:
- 去中心化(無 coordinator)
- agent 互相 handoff(任務在 agent 間流動)
- 靈活但難 debug
何時用:
- 創意發散任務(brainstorming、artistic collaboration)
- 不確定哪個 agent 該主導
框架:OpenAI Swarm(experimental)、CrewAI 部分模式
3. Mesh(點對點)
架構:
[Agent A] ←→ [Agent B]
↕ ↕
[Agent C] ←→ [Agent D]特性:
- 每個 agent 都可跟其他通訊
- 對等協作(無中心)
- 複雜度最高
何時用:
- 複雜協商(談判、議價)
- 多視角辯論(AutoGen 的辯論模式)
4. Hierarchical(階層)
架構:
[Executive Agent]
↓
[Manager A] [Manager B]
↓ ↓
[Worker] [Worker] [Worker]特性:
- 多層級(Exec → Manager → Worker)
- 權責清楚
- 適合大型企業流程
何時用:
- 企業流程模擬(總部 → 分公司 → 部門)
- 複雜決策樹(多層審批)
決策樹
任務複雜度?
├── 簡單(可拆解+合成) → Coordinator-Worker(80% 選這個)
├── 創意 / 流動性 → Swarm
├── 多視角協商 → Mesh
└── 多層級流程 → HierarchicalMason 推薦:90% 開發者用 Coordinator-Worker 就對了——最穩、最易 debug、最多框架支援。
🔧 Coordinator-Worker 實作詳解
這是 production multi-agent 的主流——深入細節。
Coordinator 的責任
- 任務拆解——把使用者請求拆成 N 個子任務
- 派發——把子任務分給 sub-agent(通常平行)
- 合成——收集 sub-agent 結果,整合成最終答案**
- 不可越權執行——Coordinator 不直接做事,只規劃 + 整合**
Sub-agent 的責任
- 窄範圍——只做被指派的單一子任務
- 無狀態——每次調用都是新 context,不依賴歷史對話**
- 回傳結構化——JSON / Markdown 等可 parse 的格式
程式碼範例(Claude Agent SDK)
from claude_agent_sdk import Agent
coordinator = Agent(
name="coordinator",
model="claude-opus-4-7",
system_prompt="""
You are a coordinator. Break down the user task into sub-tasks
and dispatch to sub-agents. Synthesize their results.
Never execute sub-tasks yourself.
"""
)
researcher = Agent(
name="researcher",
model="claude-sonnet-4-6",
system_prompt="You research a specific topic. Return structured summary."
)
writer = Agent(
name="writer",
model="claude-sonnet-4-6",
system_prompt="You write articles based on research. Return draft."
)
# Coordinator 派發
research_result = coordinator.dispatch(
sub_agent=researcher,
task="Research AI agent trends in 2026"
)
article = coordinator.dispatch(
sub_agent=writer,
task=f"Write an article based on: {research_result}"
)
final = coordinator.synthesize([research_result, article])Mason 真實案例:從單 agent 拆成 1 coordinator + 2 subagent
原始(單 agent):每日 AI 新聞 triage agent
- 1 個 agent 做:爬 RSS → 摘要 → 打信任分數
- 問題:context 慢慢膨脹(摘要每篇新聞時 context 累積)
改進(1 coordinator + 2 subagent):
- Coordinator:規劃今天要 triage 的新聞清單
- Subagent 1 (摘要員):每篇新聞獨立摘要(context 隔離)
- Subagent 2 (評分員):每篇新聞獨立打分(context 隔離)
- Coordinator 合成:整理成晨報
結果:
- token 增加:從 35K → 70K(2 倍)
- 時間:從 8 分鐘 → 5 分鐘(30% 加速)
- 準確率:從 88% → 92%(因為 context 不膨脹)
Mason 的觀察:multi-agent 是「用 token 換準確率」——不是「用 token 換速度」(時間只省 30%)。
⚡ 平行任務(Parallel Tool Use)
何時平行有意義
獨立任務:爬 10 個 RSS feed → 平行(每個 feed 獨立)
有依賴:生資料 → 摘要 → 打分(序列必須)
4-7x token 倍率實測
Mason 對「爬 5 篇新聞 + 摘要 + 排序」做對照**:
| 模式 | Token | 時間 | 倍率 |
|---|---|---|---|
| 單 agent 序列 | 35K | 8 分鐘 | 1x |
| 單 agent + 平行 tool use | 42K | 3.5 分鐘 | 1.2x token / 0.4x 時間 |
| Multi-agent(1 coord + 5 sub) | 220K | 2 分鐘 | 6.3x token / 0.25x 時間 |
結論:
- 單 agent + 平行 tool use 是性價比最高
- Multi-agent 適合「真的需要不同專家」的場景,不是「只想加速」**
Anthropic multi-agent research system 的 90% 平行
Anthropic 公開的研究系統(用於 Claude 內部研究):
- 90% 時間在平行任務
- Coordinator-Worker 架構
- 每個 worker 跑 ReAct(同時運用 Agent 設計模式)
意涵:business 用 multi-agent 的最佳實踐是「最大化平行」——因為 latency 是用戶體驗的關鍵。
平行 ≠ 加速:I/O bound 才賺
平行加速看「bottleneck」:
- I/O bound(等 API 回應、等資料庫查):平行賺
- LLM bound(等 LLM 算):平行也不一定賺(LLM call 可能有 rate limit)
- 計算 bound:LLM 本來就是 GPU 算,平行可能搶資源**
Mason 的觀察:真實 production multi-agent 大多是 I/O bound(等 web scraping、等資料庫、等其他 API)——這時平行真的能加速。
🩸 Context Bleeding(多 agent 最大殺手)
這節是 SERP 沒人寫過的關鍵章節——對手都在賣 multi-agent,沒人警告 context bleeding**。
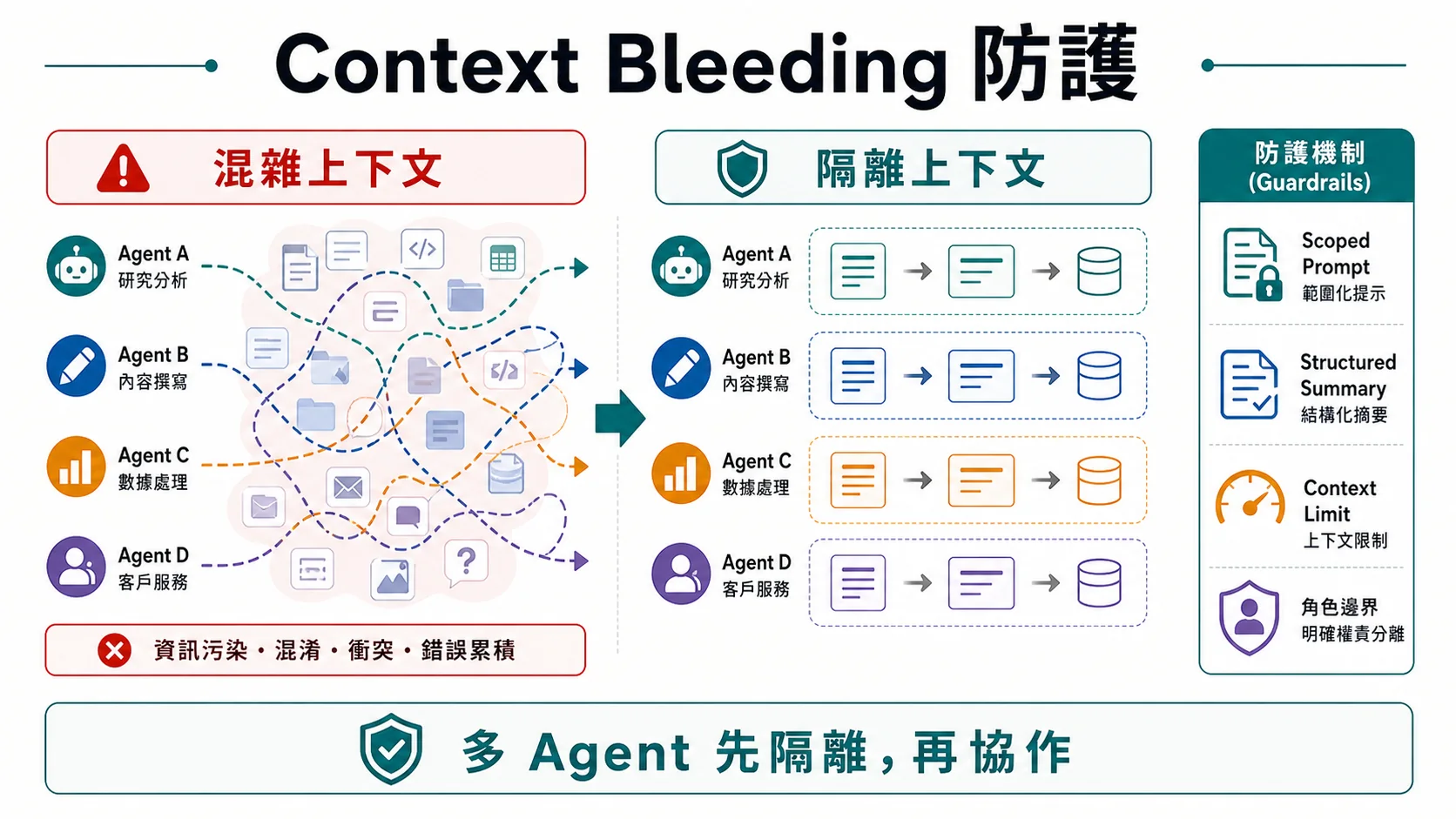
什麼是 Context Bleeding
現象:Subagent 拿到父 agent 的對話歷史——父的 context 「漏」進 subagent**。
為什麼會發生:
- 沒做 context isolation(直接把父 agent 的 messages 傳給 subagent)
- scoped prompt 寫不好(subagent 不知道自己「只該做什麼」)
- MCP server 沒過濾(MCP 預設可能傳完整 context)
3 個偵測信號
信號 1:Subagent 答非所問
症狀:Subagent 應該做「摘要 X 文章」,結果回答「整理今天會議紀錄」。
原因:父 context 有「整理會議紀錄」任務,subagent 看到後優先做這個。
信號 2:Token 爆量
症狀:Subagent 第一個 task token 9K,第 10 個 task token 850K**。
原因:Subagent 每次都拿到累積的父 context——越用越大。
Augment Code 報告:typical multi-agent 系統 token 倍率 8.5x——多半是 context bleeding 造成。
信號 3:結果不一致
症狀:同樣 prompt 給 subagent,第 1 次答 A,第 2 次答 B。
原因:父 context 在不同時刻不同,subagent 受不同的「洩漏 context」影響。
4 個防護機制
防護 1:Context Isolation
做法:Subagent 用全新 message list,不繼承父 context**。
# 錯誤(context bleeding)
subagent.run(messages=coordinator.full_messages)
# 正確(context isolation)
subagent.run(messages=[{"role": "user", "content": specific_task}])防護 2:Scoped Prompt
做法:Subagent 的 system prompt 明確說「只做 X、不做 Y」。
你是專門做「**新聞摘要**」**的 sub-agent。
【你只做】:
- 把給定的新聞文章摘要成 200 字內
【你絕對不做】:
- 翻譯
- 評分
- 推薦
- 整理會議紀錄
- 任何超出「**摘要**」**的任務
【輸出格式】:
{"summary": "...", "word_count": N}防護 3:Structured Summary
做法:Sub-agent 回傳「結構化 JSON」,Coordinator 只解析 JSON,不繼承 sub-agent 的對話歷史**。
防護 4:Context Window 限制
做法:每個 sub-agent 設「最大 context size」——超過就拒絕。
subagent = Agent(
model="claude-sonnet-4-6",
max_context_tokens=10000 # 限制 context 大小
)Mason 真實踩坑
情境:第一版 multi-agent triage(2 個 sub-agent)。
問題:Subagent 1 摘要新聞時,把整個父 agent 的 codebase context 拉進來**——token 從 9K 爆到 850K——API 帳單暴增。
修復:所有 sub-agent 改用 context isolation——token 回到 30K。
對應 Augment Code 報告:typical context bleeding 倍率 8.5x——Mason 踩到的就是這個經典坑。
💰 Multi-Agent 的成本守門
Multi-agent 額外的 4 層成本:
1. 多次 LLM call
單 agent:1 次 task = 5-10 LLM calls Multi-agent:1 次 task = 30-50+ LLM calls(coordinator + 多 sub-agent + 合成)
2. 多次 tool call
Sub-agent 各自呼叫 tool——tool call 次數倍增。
3. Coordinator 合成 token
Coordinator 要看完所有 sub-agent 結果才能合成——context 大、token 多。
4. Retry / 失敗成本
任一 sub-agent 失敗 → coordinator 可能 retry 整個——重做的成本。
預算上限機制
class MultiAgentBudget:
def __init__(self, max_cost=1.00, max_tokens=100000):
self.max_cost = max_cost
self.max_tokens = max_tokens
self.spent = 0
self.tokens = 0
def check_before_dispatch(self, estimated_tokens):
if self.tokens + estimated_tokens > self.max_tokens:
raise BudgetExceeded("Token budget exceeded")
if self.spent + estimate_cost(estimated_tokens) > self.max_cost:
raise BudgetExceeded("Cost budget exceeded")詳細部署 + 監控 → AI Agent Production 部署
🛠️ Framework 選型
| Framework | Multi-Agent 強項 | 弱項 | 適合 |
|---|---|---|---|
| LangGraph | State graph 最完整、所有架構都能做 | 學習曲線最陡 | 複雜流程、需要客製化 |
| CrewAI | 角色明確(researcher / writer)、業務人能改 | 不適合複雜編排 | 內容生產、調研、簡單分工 |
| AutoGen(微軟) | 辯論型最強(agent 互相質疑) | debug 不易 | 嚴謹決策、需要多視角 |
| Claude Agent SDK | 輕量、貼 Claude、MCP 友善 | 抽象度低,需自己組架構 | prototype、Anthropic 生態 |
Mason 推薦:
- 新手 / 內容生產 → CrewAI(角色明確最直覺)
- 複雜編排 → LangGraph
- 辯論決策 → AutoGen
- 快速 prototype → Claude Agent SDK
❓ FAQ
Multi-agent 一定比 single-agent 強嗎?
不是,80% 場景單 agent 夠用**。
Mason 反潮流主張(對手都鼓吹 multi-agent):
- 任務簡單 → 單 agent
- 任務沒多領域分工 → 單 agent
- 預算緊 → 單 agent(multi-agent token 4-7 倍)
該用 multi-agent 的 3 個訊號:
- 任務有明確「不同專家」需求(研究 + 開發 + 設計)
- 平行能帶來實質加速(I/O bound 任務)
- 預算寬鬆 + 對品質有極高要求
Mason 自己:90% 任務用單 agent——只在「寫稿 + SEO + fact check」這種多領域任務用 multi-agent**。
Coordinator 跟 Sub-agent 怎麼分工?
核心原則:Coordinator 規劃 + 整合,Sub-agent 做事**。
Coordinator 的 4 個責任:
- 任務拆解
- 派發
- 合成
- 不直接做事
Sub-agent 的 3 個責任:
- 窄範圍(只做被指派的事)
- 無狀態(每次 call 是新 context)
- 回傳結構化(JSON / Markdown)
反模式:Coordinator 也做事 → context 膨脹 + 責任不清。
平行 agent 真的能加速嗎?
看 bottleneck:
I/O bound(等 API、等資料庫) → 平行真的賺 LLM bound(等 LLM 算) → 平行可能不賺(rate limit / GPU 搶資源) 計算 bound → 平行可能搶 GPU
真實數據:Mason 自己 multi-agent 平均省 30-40% 時間,token 多 4-7 倍**——ROI 不一定划算。
最划算的情境:多個 web scraping / 多個 API 查詢同時跑(I/O bound 典型)。
為什麼我的 subagent 會被父 context 汙染?
Context Bleeding——最常見的 multi-agent 失敗模式。
3 個原因:
- 沒做 context isolation(直接傳父 messages)
- scoped prompt 太弱
- MCP server 沒過濾
4 個防護:
- Context Isolation(subagent 用全新 message list)
- Scoped Prompt(明確說「只做 X」「不做 Y**」)
- Structured Summary(只回傳 JSON,不傳對話歷史)
- Context Window 限制(max_context_tokens)
Augment Code 報告:typical multi-agent context bleeding 倍率 8.5x——這就是 token 帳單暴增的原因。
CrewAI 跟 LangGraph 我該選哪個?
看複雜度 + 角色清晰度:
選 CrewAI:
- 角色明確(researcher / writer / reviewer)
- 業務人也能讀 / 改
- 內容生產、簡單分工
選 LangGraph:
- 複雜編排(多層、有條件分支)
- state machine 設計
- 需要極端客製化
Mason 自己:內容生產 multi-agent 用 CrewAI(易讀);每日新聞 triage agent 用 Claude Agent SDK + 自己組(輕量)。
⚠️ 警語
- 80% 場景單 agent 夠——別被「multi-agent 是未來」鼓吹文騙了**
- Context bleeding 是最常見的失敗模式——4 個防護缺一不可
- Multi-agent token 4-7 倍——預算守門必設
- CodeAct sub-agent 必加 sandbox——pocketos 事件 在 multi-agent 也適用
權威來源:
- Anthropic Multi-Agent Research System
- Augment Code: AI Agent Loop Token Costs
- Multi-Agent Orchestration: Augment Code
深入閱讀:➜ AI Agent Pillar | Agent 設計模式 | Agent Production 部署 | AI Agent 從零自建